
 Data preparation modules.
Data preparation modules.
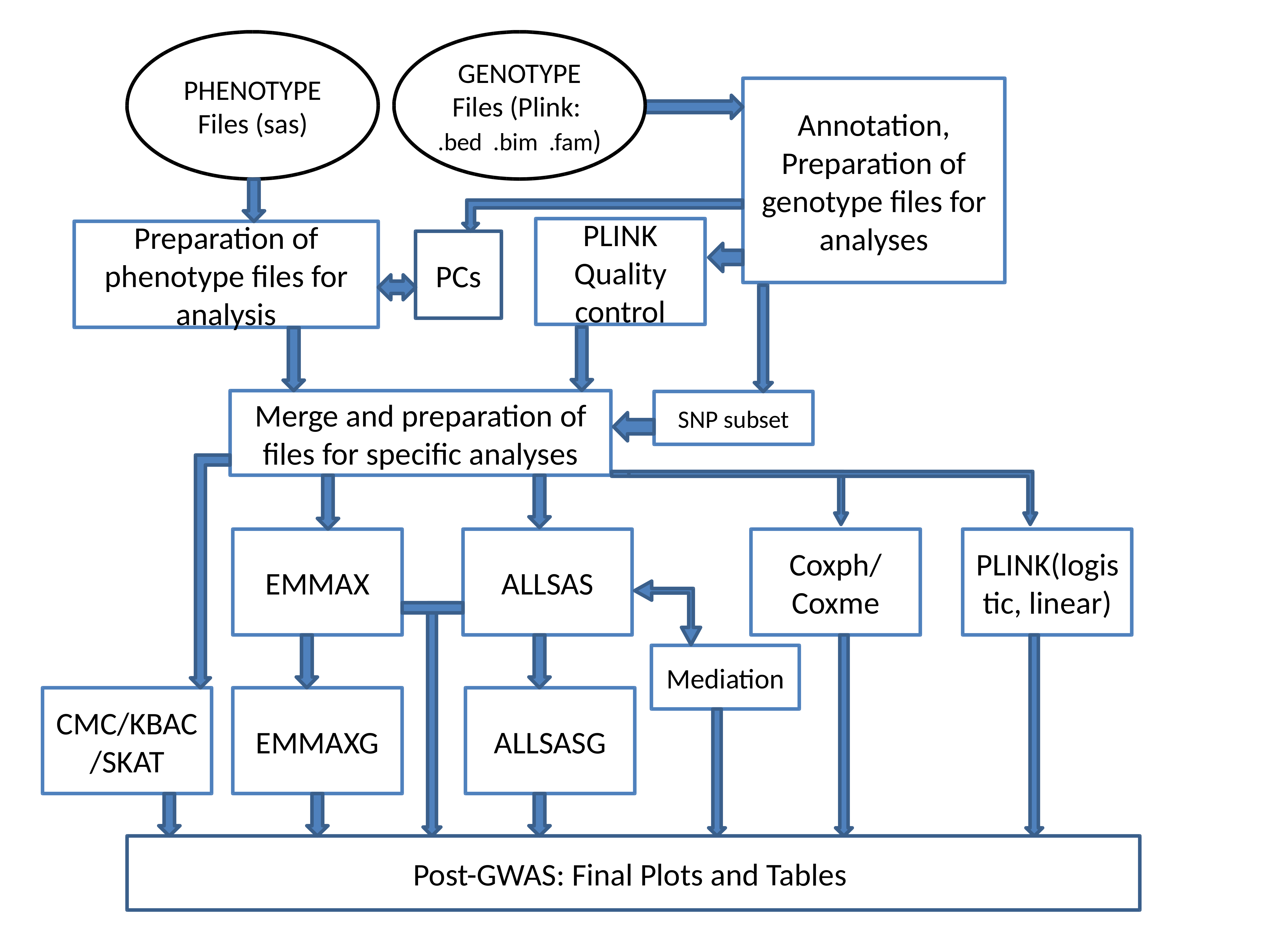
The ANNOTATION block represents a set of subroutines that perform i) the mapping of internal SNP IDs used in respective dbGaP datasets to rs-codes from the most recent release of dbSNP and the connection of SNP IDs with genes and pathways and ii) testing for the compatibility of the data and adjusting for discrepancies if necessary. The annotation part of the current version of AGAPS allows us to link information in a PLINK files to rs-code and therefore to get access to all modern information about the SNPs identified as related to a phenotype in analyses. This information will then be used to populate output tables as requested by a user.
The PC block represents the calculation of 20 (customizable default option) principal components (PCs) for use in the analysis. Users can select use of EIGENSOFT or R (GenABEL) for principal component construction. The user may also control whether all individuals or founders only will be used, and whether all or only tag SNPs will be used in calculation of principal components. As a by-product, clustering of calculated PCs is performed to obtain the predetermined number of clusters. Membership in a cluster can serve as a polygenic score. One advantage of this score is that it is constructed without using phenotype information and therefore it reflects only the actual population structure reflected in the genetic data.
The Phenotype processing block represents a step implemented in SAS that uses phenotype SAS files and prepares all of the files necessary for further steps. Note that this is not a limitation for non-SAS users, as AGAPS provides converters from SAS data files to tab/comma delimited files and back. The files are constructed based on options selected for analysis and include: individuals, covariates, and phenotype files that are used by PLINK for final representation of data for analyses. If principal components are selected as covariates they are also added to the file with covariates. The phenotype file contains binary or continuous phenotype. In the case of chosen methods for censored data, respective files are also constructed. One additionally implemented function is construction of predicted survival times for censoring individuals based on a simple demographic model.
The Quality Control block represents the PLINK step of genetic quality control based on QC-options on Minor allele frequency (MAF), Hardy–Weinberg equilibrium, and several other options available in PLINK software.
The Merge and Preparation Files for Specific Analyses block reflects a step designed to merge phenotype and genetic data for analysis. All necessary files for requested analyses are created within this step. The sub-block shows that specific genes could be selected for analyses. The respective Python code uses information from the results of annotation preparation. This option is very convenient for quick analyses of specific hypotheses about pathways or simply specific sets of candidate genes.
Analysis modules
EMMAX reflects the ability to invoke EMMAX software for calculating associations for continuous outcomes27. EMMAX allows for simultaneous accounting for relatedness and stratification in GWAS.
ALLSAS is the most used option for analyses of associations in the current version of AGAPS. Six models are currently implemented for independent and dependent individuals for categorical (typically binary), continuous, and censored outcomes. These are implemented through the LOGISTIC, REG, and PHREG SAS procedures for independent individuals and through GLIMMIX, MIXED, and PHREG with option SANDWICH for dependent individuals. A researcher can choose the number of available CPUs to make calculations parallelized. Note also, that SAS option OPENFILE is used to load the datafile into Random Access Memory in order to minimize the time-intensive use of hard disks.
The sub-block MEDIATION describes the SAS codes that we developed to perform mediation analyses of selected SNPs and a set of predetermined mediators to prove that these SNPs are related to final outcomes (e.g., longevity or survival time) only through their effects on a mediator.
COXPH/COXME provides the ability to use the respective R-package for analyses of associations of censored individuals. AGAPS automatically calculates the optimal number of CPUs that needs to be used for parallelizing.
PLINK (logistic and linear) block represent the option to use PLINK to perform association studies based on linear and/or logistic regression models.
EMMAXG and ALLSASG represent gene-level analyses using the results of estimates of SNPs by EMMAX and ALLSAS, respectively. In these analyses a set of scores (e.g., the score reflecting genetic mutations (or deficits)) is constructed and then used in association studies.
The block CMC, KBAC, SKAT represents a collection of collapsing methods allowing for the application of respective approaches to a set of SNPs in a gene (or another genetic variable). SKAT works for all types of outcomes (including left-truncated censored outcomes) while other approaches are applicable for approaches work for binary outcomes only.
POST-GWAS analyses combines the results for all performed tasks, creates final files, presents useful graphs such as QQ- and Manhattan plots as well as Kaplan-Meier curves for specific genetic variants.
Following software is required to be installed at a workstation: SAS, Python, R, PLINK, EMMAX, EIGENSTRAT.