


What is a fair price for an insurance policy? Standard actuarial thinking suggests that a fair price is the one that most closely reflects the risk (expected costs) of that policy. This type of actuarial fairness ensures that, within an insurance portfolio, the premiums collected from homogenous groups of policyholders will, on average, match the corresponding claims costs.
Nonetheless, other considerations cast doubt on such a notion of fairness. Primary among such concerns is whether actuarially fair prices systematically discriminate against particular demographic groups. Regulators have responded to such concerns by banning the use of characteristics such as sex, ethnicity, nationality, religious belief, or sexual orientation as rating factors in calculating insurance prices. Furthermore, the rise of machine learning and artificial intelligence models, trained on policyholders’ individualized information, has raised the specter of potential harms from the resulting transformation of insurance practices under the broader banner of algorithmic (un)fairness.
Discrimination by proxy
A key concern relates to the phenomenon of indirect or proxy discrimination. Even when sensitive attributes are not used as factors in pricing models, they may be implicitly inferred from other, apparently legitimate, policyholder characteristics. For instance, policyholders’ postal codes are commonly used to calculate insurance prices, but this information can serve as an effective proxy for determining ethnicity. Thus, while a policyholder’s ethnicity is not explicitly used as an input to a pricing model, it can be predicted (often with some certainty) from their postal code. Importantly, the association between postal code and ethnicity is the troubled inheritance of past (and present) discrimination, highlighting how insurance pricing practices may both reflect and amplify extant inequities.
Proxy discrimination does not necessarily take place by design. Our first paper on the topic demonstrates that working out insurance prices by ignoring sensitive attributes leads to undesired, indirect discrimination. As a correction, we provide a pricing algorithm that prevents the proxying of sensitive attributes from other characteristics. In a first step, our proposal suggests computing a price that is based on all available information, including sensitive attributes. In the second step, the protected information is “averaged out” in a way that does not use the association between sensitive attributes and other covariates. The process is illustrated in Figure 1 below.
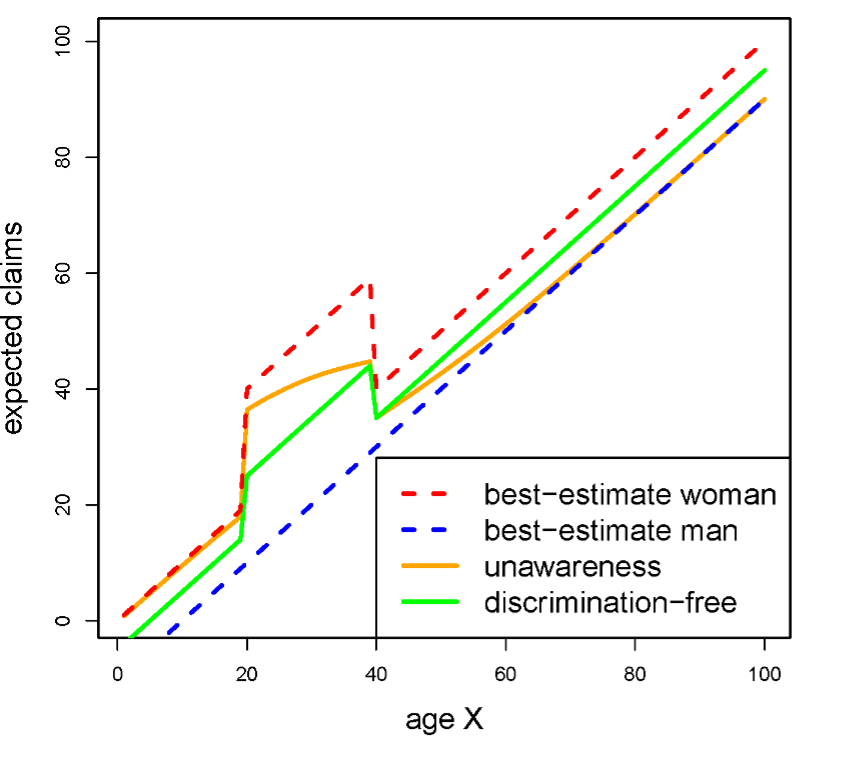 Figure 1: Illustration of proxy discrimination and corresponding adjustments in a synthetic portfolio. In this portfolio, age acts as a proxy for sex, with older policyholders being disproportionally men and younger policyholders being disproportionally women. The dashed red and blue lines correspond to the best actuarial estimates of costs for women and men, respectively – these are discriminatory and cannot be used as they are for pricing. The orange line represents unawareness prices, that is, cost estimates calculated by just ignoring sex as a covariate. It is seen that the line converges to the best estimates for women at low ages and to the best estimates for men at high ages, which is precisely proxy discrimination. The green line represents prices that adjust for proxy discrimination, averaging between the best-estimate prices for men and women with constant proportion. In particular, the excess costs for women between the ages of 20 and 40 are shared by men in the same age group. (Source: Lindholm et al. (2023))
Figure 1: Illustration of proxy discrimination and corresponding adjustments in a synthetic portfolio. In this portfolio, age acts as a proxy for sex, with older policyholders being disproportionally men and younger policyholders being disproportionally women. The dashed red and blue lines correspond to the best actuarial estimates of costs for women and men, respectively – these are discriminatory and cannot be used as they are for pricing. The orange line represents unawareness prices, that is, cost estimates calculated by just ignoring sex as a covariate. It is seen that the line converges to the best estimates for women at low ages and to the best estimates for men at high ages, which is precisely proxy discrimination. The green line represents prices that adjust for proxy discrimination, averaging between the best-estimate prices for men and women with constant proportion. In particular, the excess costs for women between the ages of 20 and 40 are shared by men in the same age group. (Source: Lindholm et al. (2023))
In a follow-up paper, we applied our method to a real dataset of motor policies. We showed that, in that portfolio, proxy discrimination had a material effect, with evidence that one ethnic group is proxied by other covariates, which would have affected the technical prices leading to insurance premiums. The impact of proxy discrimination in that portfolio is visualized in Figure 2. This demonstrates that proxy discrimination can be a real factor in insurance portfolios, though the materiality of its effect will depend on the line of business, market, and portfolio composition.
 Figure 2: Estimated claims frequencies in a real motor insurance portfolio by age and ethnicity group (1-5). All prices are normalized with reference to best estimates, which are calculated using all available information (including ethnicity). Blue dots show the claims frequencies calculated by just ignoring ethnicity. The deviation between the blue dots and the black horizontal line represents the reallocation of costs between ethnic groups, resulting from not using ethnicity as a covariate. Red dots represent estimates adjusted to also remove proxy discrimination. The difference between blue and red dots represents the potential impact of proxy discrimination – this affects mostly younger policyholders in ethnic group 1, who would have lower risk estimates under our proposed price adjustment. (Source: Lindholm et al., 2022)
Figure 2: Estimated claims frequencies in a real motor insurance portfolio by age and ethnicity group (1-5). All prices are normalized with reference to best estimates, which are calculated using all available information (including ethnicity). Blue dots show the claims frequencies calculated by just ignoring ethnicity. The deviation between the blue dots and the black horizontal line represents the reallocation of costs between ethnic groups, resulting from not using ethnicity as a covariate. Red dots represent estimates adjusted to also remove proxy discrimination. The difference between blue and red dots represents the potential impact of proxy discrimination – this affects mostly younger policyholders in ethnic group 1, who would have lower risk estimates under our proposed price adjustment. (Source: Lindholm et al., 2022)
In the effort to derive discrimination-free insurance prices, we are faced with a conundrum: adopting our approach requires, in its first step, the use of data on policyholders’ sensitive attributes. Without such information, insurers can neither assess the materiality of any discriminatory effects of their pricing schemes nor correct for them. To overcome this challenge, we propose a deep learning architecture that can produce accurate predictions, even when data on sensitive attributes are only available for a subset of insurance policies.
Demographic fairness
The discussion around proxy discrimination involves a certain technical complexity. A much simpler question may be asked: are different demographic groups charged on average the same insurance rates for the same products? If this is true for a portfolio, then the property of demographic parity is satisfied. If the average premium that different groups (e.g., ethnicities) pay differs, this can be viewed as a form of unfairness. Demographic parity is the simplest out of a range of group fairness criteria, and we restrict our discussion to this.
Requiring demographic parity in insurance pricing would be a substantial departure from the principles of actuarial fairness since different demographic groups may also be different in terms of other factors that impact their risk of making claims. Therefore, the extent of demographic disparities will be impacted by the composition of individual portfolios. As a corollary, any attempt to achieve demographic parity through pricing would mean that each insurer makes different – and hence rather arbitrary – adjustments to their actuarial prices.
The questions of demographic disparities and proxy discrimination, both arising from the correlation between sensitive attributes and other risk factors, are deeply entangled. When controversies arise, it is not clear which of the two issues forms the core of the problem. In our most recent work, we elucidate the relationship between demographic unfairness and proxy discrimination. Does one of the two imply the other? Can we address both criteria with the same adjustment to insurance prices?
The answer to these questions is generally negative. We provide examples where no proxy discrimination takes place, but demographic unfairness persists. Conversely, there are portfolios where demographic parity is achieved, but at the same time, proxy (and even direct) discrimination is present. Consequently, the mechanisms for achieving demographic parity differ from those needed to cancel out proxy discrimination. In the latter case, we rely on averaging prices over different demographic groups. To achieve demographic parity, a different operation is needed: a transformation of relevant variables (using ideas from the theory of optimal transport), either by pre-processing model inputs – as illustrated in Figure 2 – or by post-processing model predictions. However, we argue that if these transformations are not interpretable in their own right, they can lead to (new) discriminatory effects.
 Figure 3: Price adjustments, using input pre-processing with Optimal Transport (OT), in the same synthetic example as Figure 1. The orange and turquoise lines correspond to prices by age for women and men, respectively, following a transformation that adds 5 years to the age of women and subtracts 5 years from the age of men. The resulting portfolio effect is demographic parity, that is, the same average insurance price is charged for men and women in the portfolio. Note though that, with respect to the original age scale, the prices are discriminatory since men and women of the same age are priced differently. (Source: Lindholm et al. (2023))
Figure 3: Price adjustments, using input pre-processing with Optimal Transport (OT), in the same synthetic example as Figure 1. The orange and turquoise lines correspond to prices by age for women and men, respectively, following a transformation that adds 5 years to the age of women and subtracts 5 years from the age of men. The resulting portfolio effect is demographic parity, that is, the same average insurance price is charged for men and women in the portfolio. Note though that, with respect to the original age scale, the prices are discriminatory since men and women of the same age are priced differently. (Source: Lindholm et al. (2023))
Implications for regulation
Our arguments around fairness and discrimination in insurance pricing have numerous implications for regulating insurance markets.
First, proxy discrimination and demographic unfairness arise in insurance pricing as a result of the composition of portfolios, which drives the statistical (and not necessarily causal) association between sensitive attributes and other policyholder characteristics. No intent on the side of insurers is necessary for discriminatory effects to occur. If regulators do not take action, then these phenomena will persist.
Second, data on sensitive attributes are needed to quantify the materiality of proxy discrimination or demographic unfairness – and to correct for these effects. We have introduced techniques that remove proxy discrimination when only partial data on sensitive attributes are available. Still, depending on the jurisdiction and the attribute, even partial collection of such data may be problematic – this highlights the role of regulators in establishing when, how, and for what purpose sensitive data can be collected, used, and stored. Furthermore, besides legal concerns around data protection, regulators must be in a position to communicate clearly to policyholders the privacy implications of such exercises.
Third, we have shown that different criteria, namely avoiding proxy discrimination and achieving group fairness, are in potential conflict. Satisfying the one does not mean the other is satisfied too; adjusting for one may undermine the other. Hence, regulators face difficult trade-offs and the need for careful elucidation of societal preferences to calibrate their approach toward insurance pricing practices. In addition, they need to balance any such considerations with economic arguments around the operation of insurance markets, e.g., adverse selection arising from correcting for discriminatory effects. We hope that through our technical work, we contribute to clarifying the contours of such discussions.
Fourth, our view is that requiring demographic parity (or broader notions of group fairness) is not generally a reasonable requirement for individual portfolios, given its departure from risk-reflective pricing and the potential for such requirements to produce discriminatory effects. Furthermore, demographic parity requires arbitrary portfolio-specific adjustments, which will be inconsistent across a market. Nonetheless, one can alternatively ask that group fairness criteria apply across a wider population of policyholders in an insurance market, rather than within individual portfolios – such an approach would remove some of the arbitrariness of the resulting price adjustments.
Fifth, while we believe that correcting for proxy discrimination should take precedence over concern for group fairness, an important limitation should be stated. Consider the use of individualized data (e.g., wearables, telematics) for accurate quantification of the risk of insurance policies. The availability of such data may diminish the utility of sensitive attributes for predictions, making them redundant. As a result, proxy discrimination would also dissipate. Nonetheless, beyond concerns around surveillance and privacy, such individualized data may capture policyholder attributes (e.g., night-time driving) that are not just associated with race but are a constituent part of racialized experience, not least because of historical constraints in employment or housing opportunities. After all, the categorization of attributes as “sensitive” is itself a product of social histories, and apparently, legitimate covariates are correlates of such histories. Hence, there is a good reason to monitor demographic unfairness within insurance portfolios and to try to understand its sources. More broadly, the resolution of these tensions requires interdisciplinary engagement of expertise across fields such as actuarial science, law, computer science, politics, organization science, and economics.
Mathias Lindholm is an Associate Professor in Mathematical Statistics at the Department of Mathematics of Stockholm University.
Ronald Richman is the Chief Actuary of Old Mutual Insure and a PhD candidate of the University of the Witwatersrand.
Andreas Tsanakas is a Professor of Risk Management at the Bayes Business School (formerly Cass), City, University of London.
Mario V. Wüthrich is a Professor of Actuarial Science in the RiskLab of the Department of Mathematics at ETH Zurich.
This post was adapted from their paper, “What is Fair? Addressing Proxy Discrimination and Demographic Disparities in Insurance Pricing,” available on SSRN.