As courses are coming to an end, I want to reflect on 4 things that I learned as a programming instructor this summer.
1. Every Student Deserves the Chance to Explore, Advance, and Succeed in Computer Science
10 years ago, my first Computer Science teacher told me that I wasn’t cut out for the subject, and because of that, I stopped programming altogether. At Duke, I frequently felt overwhelmed by the imposter syndrome — how could I compete with my coding prodigy classmates when I just finally gathered the courage to pick up CS again in college? As my passion for CS and education grew over time, I went into this summer with a deeply personal goal: Become that inspiring first instructor who encourages students to further explore the ever-fascinating field. To me, every student deserves the chance to explore, advance, and succeed in CS, no matter their age or background. Learning CS undoubtedly helps students acquire valuable technical skills in our rapidly changing world. But more importantly, if taught right, the subject teaches problem solving, encourages creativity, and inspires innovation. To make sure my students are not discouraged while learning CS, I have done the following throughout my courses to personalize each student’s learning path:
- Varying Difficulties for Assignments:
For each assignment, I release two versions: one for those who feel less comfortable and the other for those who feel more comfortable. Students can submit either or both, in which I count the submission with the highest score. That way, struggling students are not overwhelmed and excelling students can still feel challenged by the problem sets.

- Small Group Office Hours and Individual Meetings:
As a huge proponent of creating meaningful relationships with students, I enjoyed holding office hours and individual meetings that allowed me to get to know my students better. I also thought it was helpful to be able to walk through problem sets and projects step by step with students. When I first started learning CS, I often felt lost when given a difficult problem and simply told to solve it. In office hours, I am able to show students how I approach a problem from scratch:
- Brainstorm program design through charts and graphs
- Apply decomposition and abstraction
- Test functions incrementally
- Debug using print statements, test cases, and stack traces
- Evaluate program design and efficiency
I believe merely introducing these methodologies is not enough. By going through a practical example and voicing my thoughts out as I code out sample solutions, students can apply effective strategies that I use when they feel stuck in their own development cycles.

2. Analogies are Amazing
When the vocabulary is technical, students are less likely to trust that they know the answer, even when they actually do. Putting technical ideas into familiar, real-life settings effectively reduces the fear associated with classroom discussion. Thus, when I’m introducing new CS concepts, I make sure to draw on plenty of analogies to simplify abstract concepts and encourage further discussion. Since students are more likely to personally connect with these everyday examples, I find that they have a much easier time comprehending and implementing code later on.
Here are some examples of how I use real life analogies to explain CS concepts:

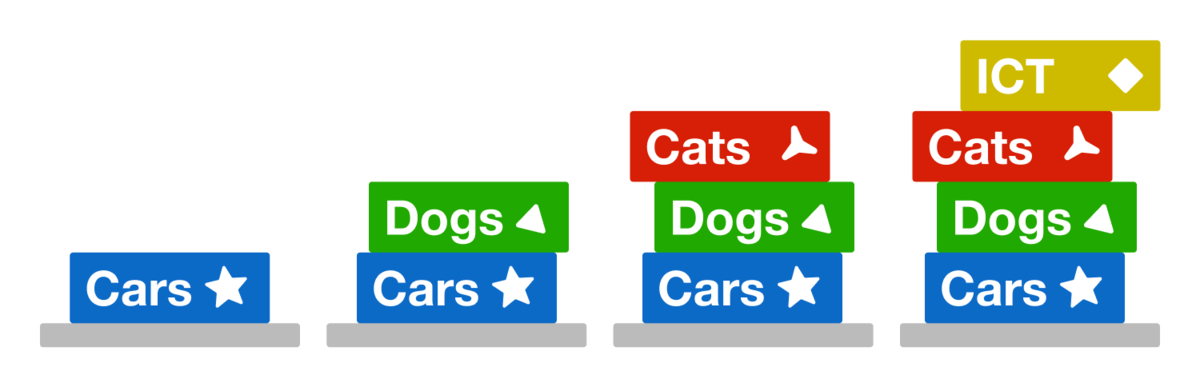
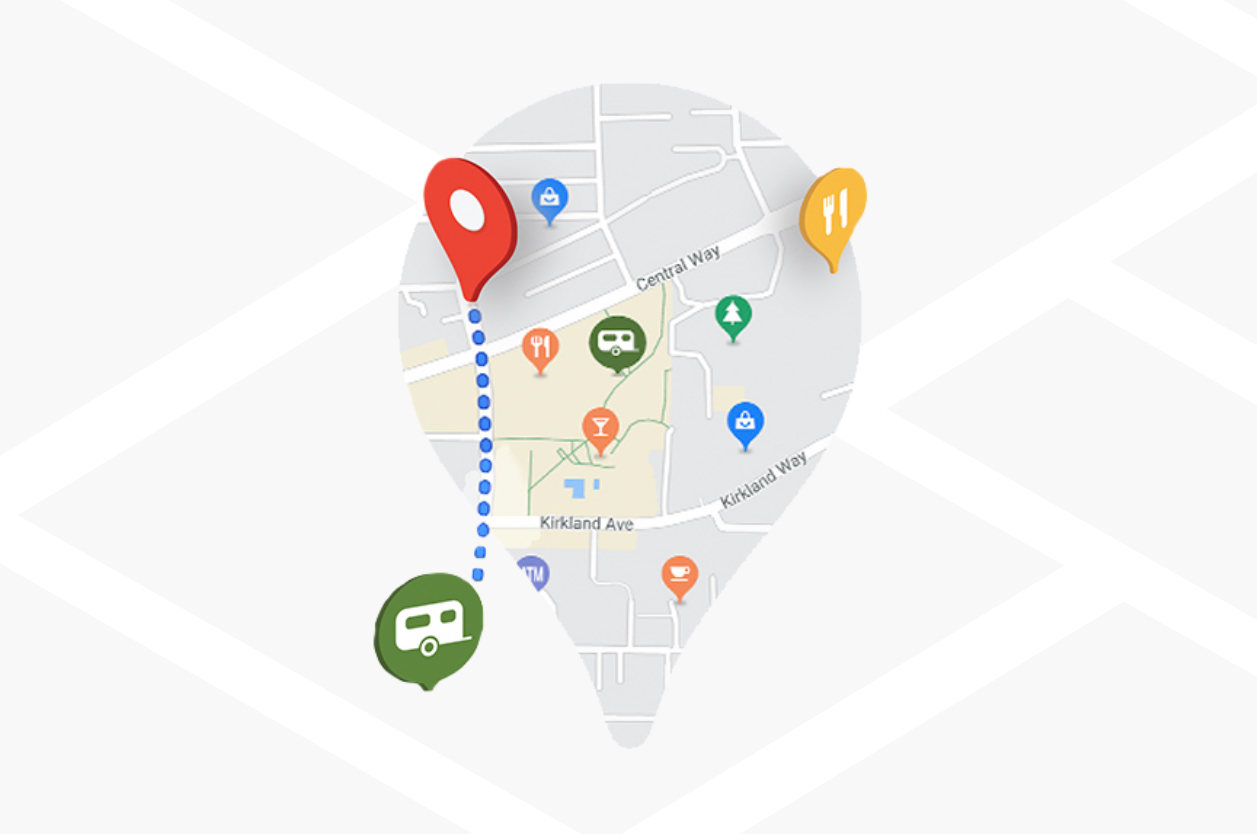
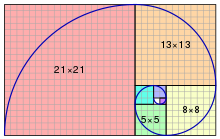
3. Creativity > Memorization
When I first learned CS, I spent most of the time memorizing templates in order to pass tests. Looking back, I didn’t understand the essence of CS. Having syntax and library functions memorized doesn’t automatically make you a great programmer. Great programmers are problem solvers and innovators, and it doesn’t really matter which programming language they use , because languages are just tools after all. With an innovative mindset, we can do so much more ― identify worthy problems, come up with transformative ideas, and implement tangible solutions. To be truly impactful, we must be innovative first. Thus, I put a lot of emphasis in fostering student creativity when designing my courses.
- Open-Ended Homework and Projects:
I structure the homework assignments that I release into two parts: 1. Guided subproblems that have step by step directions for students to follow. 2. Open-ended features that allow students to inject their creativity. For example, for a Java graphics assignment, the open-ended part was to create a mascot that will be optionally entered into a class-wide graphics contest. For a video game project, the open-ended part was to allow students to add background music, sound effects, and additional levels. While I provide some hints for general directions, the specific ideas and their implementations are up to each student to explore.
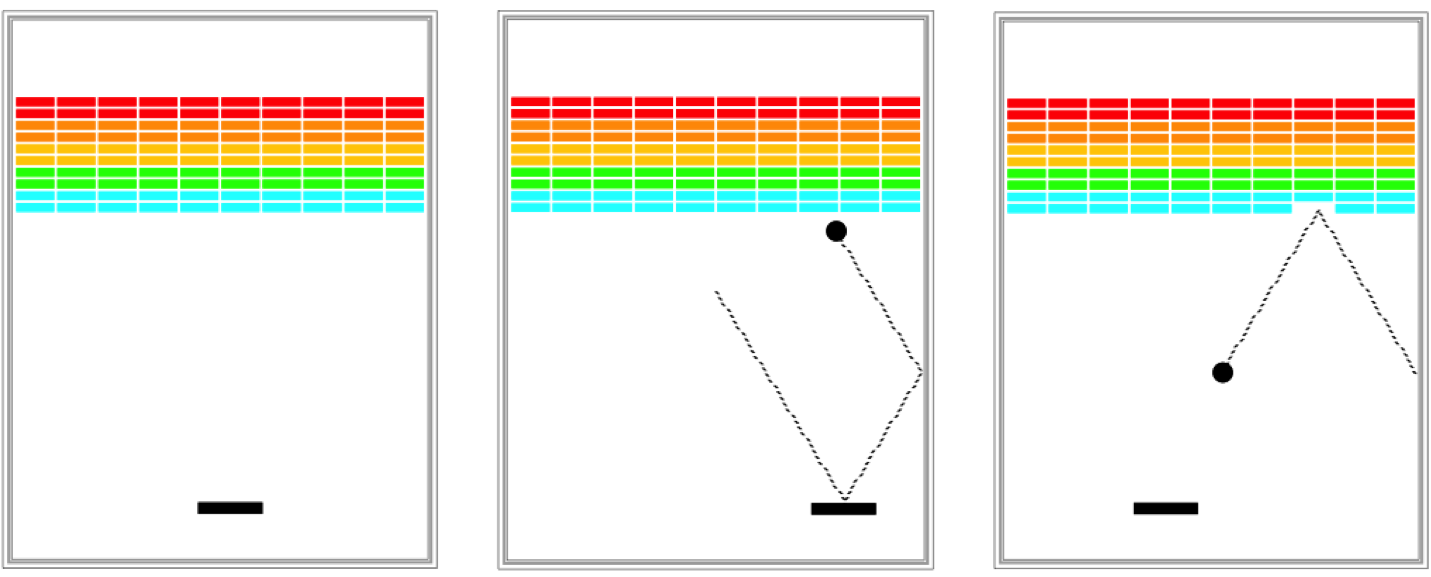
4. Learning Never Stops
In my opinion, the best way to learn is by teaching. Here are some ways that I learned as I taught:
- Being Challenged by the Unfamiliar:
At times I was challenged to teach a topic that I don’t feel as comfortable teaching. Since it is crucial for a teacher to be able to demonstrate mastery of the topic and answer student questions eloquently, this responsibility motivated me to spend substantial time reviewing before I teach a topic for the first time. For example, when teaching memory, file manipulation, and image filtering, I thought my most familiar languages, Python and Java, abstracted away too many important low level details that illustrated how computer memory works underneath the hood. Therefore, I chose to teach this segment of the course in C, a language that I wasn’t too familiar with. To teach and come up with assignments in C, I spent a tremendous amount of time studying C style, libraries, pointers, and other features through online videos and resources. Having to teach the topic motivated me to learn more efficiently.

- Learning from Students
In class, I try to maintain a passionate tone and ask the right questions as I lecture. Students often reciprocate with active participation and sometimes their responses or follow-up questions help me learn something that I wasn’t aware of before! It’s perfectly normal to not know something even as a teacher. When I don’t have a confident answer to a question, I preface that I am not completely sure, give students my preliminary thoughts, and try to find out the answer through a quick Stack Overflow search together. This way I not only make sure that I don’t spread misinformation, but both my students and I also walk away learning something new. Inside and outside of class, hearing different takes on a concept and seeing diverse code implementations to solve a problem exposed me to a wide range of perspectives, enhancing my own understanding. Every time I teach, I gain a newfound appreciation for the subject through my students.
I am a lifelong learner passionate about education and technology. Throughout the process teaching programming, I was able to help others gain technology literacy, improve my own knowledge, and create long lasting relationships!