

Can be watched here.
Augmenting Realities w/McKenzie Wark – a Storify of Tweets
September 25th, 2013 | Posted by in Uncategorized - (0 Comments)My @DukeU #augrealities course discussed @mckenziewark #gamertheory today. Conclusion: Gamespace = cyberspace = life http://t.co/d3synKtQ2W
— Amanda Starling Gould, PhD (@stargould) September 26, 2013
@stargould @DukeU What's the opposite of 'augmented' reality?
— chica marx (@mckenziewark) September 26, 2013
See the full exchange, plus a bonus conversation about games wherein death IS death, here:
Funny Representation of How Technology Affects Our Lives
September 21st, 2013 | Posted by in Uncategorized - (1 Comments)I saw this and thought about how it connected with our discussion about how technology is affecting the way we act and think. It also made me lose a little bit of faith in humanity, if the tweets are genuine. As ridiculous as it may be, it does show how we are becoming more dependent on our connection to a virtual world and how priorities have changed as technology becomes a greater part of our lives.
http://www.buzzfeed.com/jwherrman/19-ways-ios-7-is-the-apocalypse
The digital humanities project, “The Future of the Past” is a unique use of digital humanities methods. When scrutinized under the figurative lens of Shannon Mattern’s Criteria for Evaluating Multimodel Work, one can understand why it awarded “Best use of digital humanities project for fun” by the expert consortium administering the annual DH Awards: It is fun but it is perhaps not entirely effective. To simplify her criteria we made our own rubric to analyze it.

Screenshot of the Rubric we created to simplify the Mattern Criteria
For readers unfamiliar with the project, a brief overview can be found on the website by clicking “the story…” on the right side of the homepage. This provides an overview of how the author, Tim Sherrat, turned 10,000 newspaper articles into a digital humanities project. His aim was to archive every Australian news article from the 19th and 20th centuries that contained the phrase “the future” and create a site to explore how the future was perceived in the past. Sherrat’s website includes evidence of research, links to his sources, and links to/from his site to reinforce his underlying thesis in a cohesive manner. That is, that throughout time the future has been discussed throughout the past in different contexts. On the website , a link can be found to the newspaper he used which demonstrates use of citations and academic integrity – imperative components of Mattern’s ideal digital humanities model.
He extracted every word from his archive of collected articles containing the word ‘future’ and made a database. He then made an interactive word-based interface so that whenever a reader accesses the site they find a compilation of words from the articles that act as hyperlinks.

Screenshot of the Homepage of the DHP
It is through this organization that he was able to take the newspaper articles and recontextualize them into a format useful for his digital humanities project. One particularly impressive aspect of Sherrat’s project was how much feedback he
received – and his constructive dialogue with users – throughout the developmental stages of his site . Clicking “The Story” allows the site’s viewers to follow Sherrat’s creative process. Additionally, he live tweeted his progress in real time, and people tweeted at him with questions about his project, which he appeared to happily reply to. These tweets act as a form of pseudo-peer review. A series of lectures explaining his project allowed additional public understanding. This would not necessarily be considered a form of collaboration, as he was and continues to develop this project on his own, but the public input serves a form of joint effort.
Exploration of the website, and use of the tools he provides make it easy to deduce that Sherrat has a very clear vision, and a comprehensive understanding of the mechanisms behind his project. However, the format of the website is the project’s biggest downfall – the tool is simple enough to use (user friendly) because one just points and clicks, but there is no balance with something new other than the format of site. Despite the simplicity of the point and click if someone were to come to the page on their own it would be difficult for them to grasp what the site was attempting to achieve. Although it does not initially appear accessible, reading “the story…” provides some clarity. Additionally, if one came to the site to learn about how others viewed the past, it would only be a random acquisition of knowledge rather than a particular route. A direct search for a particular year, event, or phrase is not possible which makes it less useful then one would hope for. Perhaps we are not entirely grasping what he is trying to achieve which would make our critique a little unfair. If he is trying to achieve a database to allow for random knowledge acquisition (which is maybe suggested by winning the Fun category) then he effectively created such a database. From our perspective, however, it appears as if this is not the most conducive format for this project, because you cannot purposefully acquire knowledge.
Despite our inability to determine the exact purpose of the site we will proceed the rest of the way under the impression that it is made for random knowledge acquisition. Under these conditions it is appropriately formatted and effectively organized. The fact that each time you open the page a random subset a words appears, which will lead you on a different path each time, is an innovative way to create a site and to organize this information. But how well this page is linked together, its cohesiveness, is arguably the most difficult criteria to judge. If it is judged based on the understanding that it is supposed to be random then yes, the fact that it is a jumble of words that allows you to arbitrarily click on an appealing word and learn more is fantastic. Conversely, if a reader wants to acquire specific data then we would dispute how cohesive the page is.
Since Sherrat appears to demonstrate a mastery of the tool it is therefore adaptable. Mastery correlates with adaptability because a complete understanding of how the tool (the tool being the way he tied together all the words) suggest that changes could be made if the site needed to adapt. It is this adaptability that is one of the most exciting aspects of the project. If he were to come across more data he could expand upon the comprehensiveness of the database. Currently, the data is limited to a certain time and geographic range (Australia). However, if he were to collaborate with partners in various nations he could expand upon the database so that readers could learn “The Future of the Past” of more nations across a longer expanse of time. With such an extensive database, readers could compare not only “the future” across time, but across space. Another improvement we would suggest is a more comprehensive explanation of how to use the site because a better understanding allows for a more user friendly experience. Wouldn’t it be nice too to have different navigation interfaces if the world-link interface is not useful to you? If the back-end database is robust and adaptable, we should be able to feed that data into multiple interfaces allowing for very different web ‘faces’.
Based on Shannon Mattern’s Criteria, Sherrat created an approvable digital humanities project. It fulfills most of the requirements she presents, and its adaptability allows for it to potentially fulfill the rest. Overall, it is an impressive project that understandably won the award for “Best use of digital humanities project for fun.”
Co-Authors: Shane and Joy
Thank you to Amanda Gould for her assistance in reviewing our work
Preserving Virtual Words Evaluation
September 16th, 2013 | Posted by in Uncategorized - (1 Comments)The following is a critique of the “Preserving Virtual Worlds” digital humanities project.
The Preserving Virtual Worlds project, modeled after other digitization works such as Google Books, seeks to archive past and present video games. According to the Executive Summary in their final report, the authors found that video game archiving brought a very specific set of challenges and media related questions [1].
The aims to preserve what is referred to as a “virtual world.” “Virtual worlds are software artifacts, communities, and commodities” [1]. In practice, this means archiving the worlds created by video games so that in the future there exist records and playable versions for people to experience. In a game such as “Spacewar!”, preserving the world is as simple as keeping the code and hardware. For other games, the project has made attempts to capture the atmosphere of these games by compiling screenshots, descriptions from manuals or guidebooks, and videos of gameplay. For instance, the project website<> links to this source of DOOM videos and articles. The site provides records of what DOOM is like, as described by DOOM players. This preserves an aspect of the community surrounding the game, which the project views as a vital component of the “virtual world.” These archives may help people who cannot physically play these games to appreciate their virtual worlds. They may also help give an impression of certain players’ views of DOOM’s world to people who might find the game’s primitive graphics and interface alienating.
Most of the challenges faced by this project can be split into two categories – infrastructure and disputes over intellectual property rights. The greatest infrastructure issue stems from the wide range of hardware used to run video games. Some of the oldest games the project preserved – “Spacewar!”, for example – ran on punch-card computers that are no longer in production. As a result, in order to preserve it in its original form, the computer used must be maintained, along with the actual program. Many modern games designed to run on Windows also face issues. Not all games run on all graphics cards or processors, and as a result several different system configurations must be maintained. In addition, some games won’t work on newer operating systems, and those too must be maintained. The project has assembled guides for running now outdated computer programs on modern systems to allow more backward capability.
Moving forward, the project may face difficulties deciding how to preserve a game. Many games are released for multiple consoles, often involving very different methods of play. For instance, Call of Duty can be played on a computer with mouse and keyboard, or on an xbox with a controller. Do players across systems experience the game differently? The nature of a virtual world can also change across consoles. Players using PC’s can access the source code of the game and customize content. Should these exploits, or at least the potential for such exploits, be counted as part of a virtual world? The project has not made efforts to address this concern.
There are greater questions and challenges proposed by more interesting and widely played games such as World of Warcraft. World of Warcraft is a massively multiplayer online game, and as a result has millions of characters which make up its “virtual world.” Arguably, preserving a single copy of the game does not accurately capture its essence. Instead, the millions of characters must be preserved, and still it is nigh impossible to recreate the atmosphere of the game with the raw data.

Consider the game “Journey” for PS3, where the player’s character is shrouded and only utters musical notes throughout the entirety of the game. The gameplay is exploring a desert and unraveling a deep story to give context to the adventure. While this can be preserved by simply saving the data, the game also offers for other players to join in and help other players. The players have no communication, but are able to call to one another and assist each other in reaching otherwise unreachable places. This aspect of the game’s world may be lost in preservation, as it is difficult to recreate a community atmosphere and the anticipation of random encounters.
In terms of intellectual property, the authors found that it was a challenge to acquire proprietary software from companies. For example, Linden Lab, the maker of Second Life, was unwilling to hand over the code for their servers [1]. Without the server code, any copy of the game is useless if Linden Lab decides to turn off the game. Much of that type of software is maintained and upgraded and is therefore hard to retrieve for preservation purposes. As a result, most of the games preserved are old enough that rights holders are no longer protective of the source material. For games that rely on multiplayer components, this is a crippling limitation. Those games rely on a server infrastructure being in place, and unless companies give up a server, they cannot be truly preserved.
Much of the authors’ focus surrounded the archival of the game “Second Life” [1]. “Second Life” is a massively multiplayer online game where players live out a “second life” through a customizable game avatar. In many ways, the experience of playing “Second Life”] is defined not by the players individually, but by the community surrounding them. The game allows players to buy property, hold jobs, and in fact features an entire, functional economy. Some players design their avatars not as they personally view themselves, but as they want to be viewed by other players. In order to preserve this world, one must capture the relationships formed between players, as well as the social trends, which spread throughout the community.
Unfortunately for the authors, all server components developed for the game were closed source. In addition, due to the Terms of Service of the game, players retained intellectual property rights to the objects they created in the game. As a result, it was impossible for the authors to simply copy the data without explicit permission from all the residents of that section of the simulation. In the end, without access to server software, the authors were only able to archive metadata representative of a Second Life island along with metadata] from players who gave permission for their objects to be used. This metadata was simply a description of the features of the objects – the general shape and layout of the island as well as player objects.
This left the project unable to recreate the defining aspects of Second Life’s virtual world. The game features a physically large world that is populated and altered by the games millions of users as they customize the aspects of their avatars’ daily lives. Although the project has made great efforts to preserve the layout of several islands in great detail, this amounts to documenting the consequences of players’ decisions, such as customizations made to houses, without presenting what it was like to “live” in this community. Playing the game on one of these islands would be akin to wandering through a ghost town. The layout of the world has been archived, but the world has not been preserved.
Though the project has its limitations, it is based on an admirable premise. As media such as video games continue to develop in depth, they can produce both beautiful visuals and stories. They are often compared to interactive movies, adding extra depth and giving the player choice. It is important to preserve these artifacts like we do movies and books, and this project is a well-envisioned first step into the realm.
In the future, it would be interesting to see these archives of games made publicly available. Part of the benefit of digital preservation is redistribution. While some of the games are still protected by copyright and licenses, it would be great to see them made available to the public – much like the Library of Congress’ classic movie library.
[1] McDonough, J., Lowood, H., Kirschenbaum, M., Krauss, K., Reside, D., Donahue, R., & Phelps, A., et al. (2010b). Preserving virtual worlds: Final Report. National Digital Information Infrastructure Program.Washington, DC: Library of Congress
Co-Authored by Matt Hebert and Sai Cheemalapati
We chose the ORBIS: The Stanford Geospatial Network Model of the Roman World digital humanities project to critique. As an interactive software model of Ancient Roman infrastructure, ORBIS is a collaborative effort between historians and information technology specialists at Stanford University to augment modern research about Ancient Rome. The project attempts “to understand the dynamics of the Roman imperial system as a whole” [1] by allowing scholars for the first time to analyze Roman transportation costs in terms of both time and expense.
The mapping application works by allowing users to choose a start and destination location from the 751 sites, prioritizing based on fastest, cheapest, or shortest, and selecting from network and transportation mode options. The application then outputs distance, duration, and cost in denarii based on the options selected. Rebecca J. Rosen, writing for The Atlantic, describes ORBIS as “Google Maps for Ancient Rome” [2]. ORBIS was designed as a tool for scholarly study of the Ancient World but has garnered popular interest on the internet as well as a fun tool for people to explore history.

ORBIS gives a distinct impression of being the product of the rigor and attention to detail expected from academic work. The entire creation process of ORBIS has been outlined clearly on the ORBIS website. The creators acquired all their data from previous scholarly works, and all outside contributions are explicitly credited. Furthermore, the ORBIS mapping tool is available for public use online, and there are plans to make the ORBIS API public.
The creation process of ORBIS and ORBIS itself have had a significant impact on the study of the Ancient Roman world. Not only was the project horizontally integrated in the sense that it brought together history and the digital humanities, but it was also vertically integrated in that tenured professors and graduate students worked together to create the final product. Despite the fact that it was only recently created, ORBIS has already been a key feature of 5 papers and 15 presentations. In addition to allowing historians to have a better general understanding of Ancient Roman transportation systems, it has also been applied to specific problems such as explaining maritime freight charges.
ORBIS does a great job of explaining both the historical and modern sources from which they formulated the aspects and assumptions of their model. The 751 sites included in the interactive map were chosen and named based on Talbert’s Atlas of the Greek and Roman World. The three modes of transport incorporated into the model (sea, road, and river) are all evaluated based on routes, time, and expense. All of the metrics included in evaluating these factors are clearly explained by ORBIS and sufficiently enriched by supporting media. For example, the sea transport time variable is determined by winds, currents, and navigational capabilities. Monthly wind data for the Mediterranean and the Atlantic were derived from the National Imagery and Mapping Agency 2002. Additionally, the algorithm employed in accounting for navigational capabilities was compared against over 200 historical documents of sailing times.
In order to determine the central thesis that the ORBIS project asserts, we examine the choices that the creators made regarding what include and emphasize in their model of the world surrounding Ancient Rome. As mentioned above, the authors themselves say that the goal of their project is “to understand the dynamics of the Roman imperial system as a whole”, so we consider their decisions within this context. The only clear decision that the authors made for what to include was that the authors chose to focus on financial and temporal transportation costs to, from, and surrounding Ancient Rome, which implies that they believe that transportation costs are an important aspect of understanding the dynamics of an empire. This is not a particularly bold thesis, as the vast majority of the historical community would likely agree that transportation costs are a fundamental part of understanding an empire. Furthermore, the form of the work (i.e. software that allows for the creation of maps modeling Roman transportation costs) mostly takes this assertion for granted, rather than functioning to further contribute to the argument. It is therefore not as productive to evaluate ORBIS as a humanities work that is creating an argument. Instead, we can think of ORBIS as a powerful tool for augmenting research regarding Ancient Rome and evaluate it as such.
One weakness of the ORBIS project is that it has not been formally peer reviewed. While a more traditional academic paper would need to be evaluated by independent researchers in order to be published. ORBIS has not been held up to such standards because it was simply published online. While ORBIS is now being used to create more traditional papers that will necessarily be peer reviewed, it is not clear that ORBIS and the software it uses will be held up to the same levels of scrutiny. All things considered, however, this weakness is not as concerning as it would be for other academic works, as it is likely that the only reason ORBIS has not been peer reviewed is that there is not currently a formal system for peer review in the digital humanities
In January of 2012, programmatic access to some routes and site data was opened via API release. “Thanks to the efforts of the Pelagios Project, by mapping many ORBIS sites to place name entries in the Pleiades digital gazetteer, ORBIS is now (modestly) a part of the Linked Open Data cloud.” This moderate attempt at open sourcing some aspects of the project have now made ORBIS more open to independent critique or analysis and opened up the project to contributions from outside sources. The ORBIS web mapping application also operates with a lot of open source software. The website, including both the web map and text ‘article’, are described as a work in progress so ORBIS has plans for continuing development.
— Written collaboratively by Craig and David
Critique of the Map of Early Modern London
September 15th, 2013 | Posted by in Uncategorized - (0 Comments)Critique of the Map of Early Modern London
Author: Xin Zhang
Partner: Zhan Wu
The Map of Early Modern London (MoEML) is a project aimed to give users a sense of the inhabited space of London, which gave rise to the theatrical setting of many plays. Based on the Agas map, a 6-foot-2-inch woodcut of London dating from the 1560s, the project maps the streets, sites, and significant boundaries of London from 1560 to 1640 and incorporates a detailed gazetteer , topical essays, and digital texts from that period. It now comprises four main parts which are a digital atlas of Agas map, an encyclopedia of early modern London people and places, a library of mayoral shows and other texts rich in London toponyms and a forthcoming modernized edition of John Stow’s A Survey of London. And the heart of the project is an XML placeography incorporating over 720 streets, churches, wards, neighborhoods, and sites of interest. Places are both geo-referenced and linked to the Agas Map in order to visualize the locations in texts of the period.
By mapping literary references, the MoEML project would provoke research questions about Shakespeare and London alike. “How typical is Shakespeare’s invocation of London? How do his characters move through the urban environment? What is the relationship between London and the Court in Shakespeare’s historical vision? How does his geographical vision compare to that of other playwrights, such as Thomas Heywood, and to that of historians like Holinshed and Stow?” These questions entail a reconstruction of the historical space. As the director of the project Jenstad says: “think about the influences on authors, I’m thinking about the streets they lived in, where they shopped, where they went for entertainment, the route they must have taken to walk down to the bookseller who published their book, the specific environment in which people bought the book.”
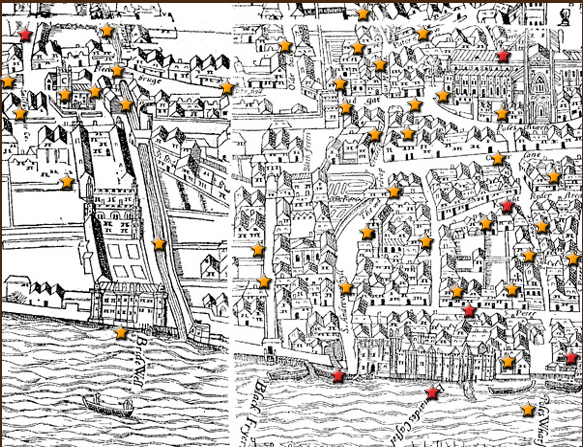
Figure. 1. Part of the Agas map marked with stars. The places marked with red stars are ones that have been edited as entries in the encyclopedia. The places marked with yellow stars are ones that are not written into the encyclopedia due to lack of knowledge.
The project invents a new way for us to study literature as it maps the places in literature and it is also a great tool to learn more about culture and history as literature is always based on some reality of that time. The researchers searched digitized texts from the 1560s for place names of early modern London and then matched those to the right places on the 1560s Agas woodcut map of London. In this way, they make use of the digitized texts with data mining programs. And they also make links to relate every place name to the texts where they are mentioned. For some places they mark red stars, the links are related to an entry of the encyclopedia for users to learn more about the history and culture about them. For some undetermined places, they will show the mark “?” to remind you that their identity may be disputed, and thus allow readers to be involved in the effort to identify them. Although it is a remarkable project, I think fails to extract deeper layers of data. It only marks the place names and links them to the related texts. However, it does not indicate all the toponyms in a specific text and their frequency. For example, when I read Richard III, I cannot grasp the distribution and frequency of the theatrical loci in the play. The project can use the current database to develop more functions than are found in the current version: it could show the places mentioned in a play and mark them according to the ; frequency referenced; it could aggregate the distribution of toponymes in the entire corpus of an author; it could show the trend of changing frequency of places being mentioned in the literature of that time to gather “narrative evidence” for the social development process. It could simply do much more.
This project makes progress by integrating cartography in the archaeology of literature. It is a useful tool for scholars to study the history and culture of early modern London and it is an attractive feature for the students to develop interest in texts. Although such a digitized Google-style map enables readers to zoom in, search and read related texts, the map is not visually appealing with only black and white colors. With the help of modern graphic technology, the map could be made colorful and three-dimensional like the Google map. In that case, it will attract a wider audience and promote learning of English history and literature among the general public.
Being open-source, the website not only provides information for other researchers but also allows users to help optimize the website. And the interface has two different versions to cater to different tastes of the users. The website seems difficult for new users as it has no manual to tell them how to make use of the website and it is not immediately clear how to use it. This is really a big mistake because such lack of accessibility turns potential users away. And it also lacks links to other relevant projects, which hinders other researchers to make cross references.
This website satisfies various criteria of an academic website. The fact that undergraduate students contributed to the project underlies its educational value. In the history of MoEML, the researchers recorded their research process which allows replication and generalization of the research procedure. It is continuously kept up to date with the latest scholarship. All the credits and citations are clearly listed which shows a good academic integrity.
The Map of Early Modern London is a creative project which highlights the spatial dimension of literature and at the same time provides indexed reference to massive amount of texts. But it has much potential of improvement.
SOURCES:
MoEML. Ed. Jenelle Jenstad. Social Sciences and Humanities Research Council, n.d. Web. 22 Sept. 2013.
Google Style Map: http://lettuce.tapor.uvic.ca/~london/imap/htdocs/
Digital Humanities 2013. Proc. of DigitalHumanities2013. N.p., n.d. Web. 03 Oct. 2013. <http://dh2013.unl.edu/abstracts/ab-180.html>.
HOWARD, JENNIFER. “The Chronicle Review.” Rev. of Literary Geospaces. Weblog post. The Chronicle of Higher Education. N.p., n.d. Web. 03 Oct. 2013. <http://chronicle.com/article/Literary-Geospaces/12442>.
#dh Project Critiques: “Speech Accent Archive” and “10 PRINT eBooks”
September 15th, 2013 | Posted by in Uncategorized - (0 Comments)Collaboratively written by Mithun Shetty, Kim Arena, and Sheel Patel
The efficacy of a digital humanities project can be vastly improved if the delivery and interface is thoughtfully designed and skillfully executed. The following two websites, “Speech Accent Archive”, and “10 PRINT eBooks”, both utilize non-traditional forms of displaying content that alter the experience of their internet audience. Both projects will be critically assessed according to the guidelines described by Shannon Mattern’s “Evaluating Multimodal Work, Revisited” and Brian Croxall and Ryan Cordell’s “Collaborative Digital Humanities Project.”
The Speech Accent Archive is an online archive of audio recordings that contains multiple speakers from a variety of regional and ethnic backgrounds dictating a specific set of sentences. These recordings are submitted by the public and reviewed by the project administrators before being added to the site. The purpose of this media element is to expose users to the phonetic particularities of different global accents. This website is useful because it provides insight regarding the various factors that affect the way people talk and how these factors interconnect – from their ethnic background to their proximity to other countries. This site proves to be a useful tool for actors, academics, speech recognition software designers, people with general appreciation for the cultural connections in languages, and/or anyone studying linguistics, phonetics, or global accents.
The website’s layout is ideal for accomplishing this purpose: users can browse the archive by language/speakers, atlas/regions, or can browse a native phonetic inventory. This allows users to explore accents on a regional basis which makes it easier to see similarities between local dialects. The audio recordings are all accompanied by a phonological transcription, showing the breakdown of consonantal and vowel changes as well as syllable structure of the passage. Each user submission is accompanied by personal data, including the speakers’ background, ethnicity, native language, age, and experience with the English language. The site also has a very comprehensive search feature which has many demographical search options, ranging from ethnic and personal background to speaking and linguistic generalization data. This level of detail is an invaluable resource for those who study cultural anthropology, phonetics, languages, and other areas, as it allows for a specific manipulation of the data presented. Also, the quality of user contributions is consistently high – it is very easy to follow the playback of the recordings.
However, the project does have its limitations as well. The passage being read by the contributors is in English, no matter the speaker’s fluency or familiarity with the language. Pronunciations of this passage may not reflect the natural sound of the languages represented. Further, because the audio samples are user-contributed, it is hard to maintain a constant of English fluency among contributors. Another limitation to the site is that many of the sections of the site have little to no recordings or data; this is merely due to a lack of user contributions, but could be resolved by website promotion. The project is still ongoing, thus the database will continue to grow as time goes on. Another limitation of the site is that it lacks any sort of comparison algorithm. The accents are all stored on their own specific web pages and load via individual Quicktime audio scripts; consequently, it is very difficult to perform a side by side comparison of accent recordings. As a result, the project is not really making any conclusions or arguments with this data. This could be improved by allowing users to stream two separate files at the same time, or by allowing a statistical comparison of the demographical information accompanying each recording. It would also be interesting if an algorithm or visualization could be created that could recognize the slight differences in the voices and arrange them based on similarity along with the demographical data that accompanies the voice sample. Further, the project could establish a tree-like comparison of regions and accents, visually representing the divergences and connections between where people live or have lived and the way that they speak.
With these additions, it would be easier to aurally understand the effects of background or ethnicity on speech accents. Still, this website shines albeit these setbacks. The project offers a tremendous amount of data in an organized manner, presenting many opportunities for further research and applications of the information. This level of detail is an invaluable resource for those who study cultural anthropology, phonetics, languages, and much more.
The book titled 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 is a collaboratively written book that describes the discovery and deeper meaning behind the eponymous maze building program created for the Commodore 64. The book can be seen as a way to look at code, not just as a functional working line of characters, but also as a medium of holding culture. 10 PRINT CHR$(205.5+RND(1)); : GOTO 10 uses the code as a jumping point to talk about computer programming in modern culture and the randomness/ unpredictability of computer programming and art. The book explores how computation and digital media have transformed culture. Along with this book, one of the authors, Mark Sample, created a “twitterbot” that uses a Markov Chain algorithm to produce and send tweets. The @10print_ebooks twitterbot takes the probability that one word will follow another, scans the entire book, and tweets the random phrases it generates.
The clear goal of this book is to demonstrate that reading and programming coding does not have to always be looked at in the two-dimensional, functional sense that many people see it as. The authors argue that code can be read and analyzed just like a book. They do so by delving into how this 10 Print program was created, its history, its porting to other languages, its assumptions, and why that all matters. They also talk about the randomness of both computing and art, and use this 10 Print program as a lens through which to view these broader topics. The purpose of this book is stated very clearly by one of the co-authors, Mark Sample: “Undertaking a close study of 10 Print as a cultural artifact can be as fruitful as close readings of other telling cultural artifacts have been.”
The implementation and format of this book and twitterbot is a little difficult to understand and doesn’t necessarily help them portray and establish their goals, especially when talking about the twitterbot. The book itself is coauthored by 10 professors who are literary/cultural/media theorists whose main research topics are gaming, platform studies, and code studies, which gives a broad range of perspectives regarding the topics. It also dives into the fact that code, just like a book, can be co-authored and can incorporate the views and ideas of more than one person. This idea draws on the parallels that the authors are trying to draw between coding and literary elements. Code is not just one-dimensional; it can incorporate the creative and artistic ideas of many people and can achieve many different forms that often have very similar functions in the end. In this sense, the co-authoring of this book inherently showcases their main message regarding code and how it should be viewed. The book also progressively talks about the history of this Basic program, and how it coincided with cultural changes due to the advent of the personal computer. Sample’s twitterbot, on the other hand, leaves the user more often confused than educated, but that may be point. Using the algorithm it spits out random, syntactically correct sentences that sometimes mean absolutely nothing, but also occasionally it creates coherent thoughts from the words in the book. The occasional coherent sentence that the bot spits out may be a demonstration of code itself. The user may see that within jumbles of code or in the case of the book, words, and meanings can be pulled if put in the correct syntax. Also, the form definitely fits. The randomness of the twitterbot allows people to see that even by coincidence there can be substance to code. If it was done having people point out specific parts of the code then we would be limited to their interpretations. Having a machine randomly spew out phrases allows for many different interpretations.
This tool, although abstractly useful could be implemented much better. If the twitter bots are “occasionally” genius, then the website would be more efficient if it had implemented some sort of ranking system for the most interesting or coincidental tweets. If they had some sort of sorting mechanism, then the project may be more convincing in saying that code can be made to have a creative license or brand.
Regardless of the various limitations both projects may have shown, it is abundantly clear that their media elements vastly improve their ability to illustrate their ideas and accomplish their purposes. It would be practically impossible to illustrate these projects with text alone. The Speech Accent Archives’ audio recordings give concrete examples to an entirely aural concept, which is infinitely more useful than simply listing the phonetic transcriptions. The 10print Ebooks’ twitterBot, while difficult to understand, is an interesting concept that also generates concrete examples of what the project is trying to illustrate – that code is multidimensional in its structure and can be interpreted and analyzed similar to a complex literary work.
Sources:
@10PRINT_ebooks, “10 PRINT ebooks”. Twitter.com. Web. https://twitter.com/10PRINT_ebooks
Baudoin, Patsy; Bell, John; Bogost, Ian; Douglass, Jeremy; Marino, Mark C.; Mateas, Michael; Montfort, Nick; Reas, Casey; Sample, Mark; Vawter, Noah. 10 PRINT CHR$(205.5+RND(1)); : GOTO 10. November 2012. Web. http://10print.org/
Cordell, Ryan, and Brian Croxall. “Technologies of Text (S12).” Technologies of Text S12. N.p., n.d. Web. 15 Sept. 2013. http://ryan.cordells.us/s12tot/assignments/
Mattern, Shannon C. “Evaluating Multimodal Work, Revisited.” » Journal of Digital Humanities. N.p., 28 Aug. 2012. Web. 15 Sept. 2013. http://journalofdigitalhumanities.org/1-4/evaluating-multimodal-work-revisited-by-shannon-mattern/
Weinberg, Stephen H. The Speech Accent Archive. 2012. Web. http://accent.gmu.edu/about.php
Critique on Digital Project “CIVIL WAR WASHINGTON” 2nd Version
September 15th, 2013 | Posted by in Uncategorized - (0 Comments)Author: Zhan Wu
Partner: Xin Zhang
Civil War Washington DH Project URL: www.civilwardc.org
The following is a critique that will evaluate a DH project about various aspects of the Civil War in Washington. The critique will be using Shannon Christine Mattern’s “Evaluating Multimodal Work” [1] as a reference in establishing various evaluation standards.
To start off, one of the most evident things in this DH website project is the overall structure, which is visually very clear. The project utilizes “tiles” in its front page. Each tile is comprised of a title and a short overall description about what the reader can expect when opening the tile URL. Every tile also contains a picture within it so that navigation around the website becomes visually easier. There are more choices that the reader can select when opening specific tiles on the front page. Opening the “Data” tile, for example, will guide the reader to different, more specific subsections, such as People, Places, Events, Organizations etc. Clicking in turn on one of the subsection links will lead the reader to even more concrete contents in the web page.

Tiles on the Front Page

Subsections of the “Data” Tile
The entire structure can be thought as a tree chart whereas one option engenders more options, which in turn give even more options and so on. This kind of structure is advantageous to scholars who intend to research on very specific facts about the Civil War in Washington without having to cram through unnecessary chunks of information. This also implies that the delivery system of the subject matter is very robust, meaning that the people making this project presented their information on the best possible platform-a website. A website enables random access to information, which is an advantage over media that use linear presentation of information, such as a paper.

Illustration of a Tree Chart.
The project uses tables, maps and pictures as its main media formats. Tables are generally utilized in the Data section and are there to list specific people, places and events related to the time. The use of tables in the DH project makes browsing through the information significantly easier. For instance, if the reader wanted to do research on the 3rd Division Hospital in DC during the Civil War, he/she would just need to go Data-Places, where there is a comprehensive list of important locations, and simply look up “3rd Division Hospital”. Search options are available and are a great add-on to the website if under any circumstances the desired content cannot be found by browsing visually through the lists and tables.
Maps are yet another media format and are a great feature on the website. There is a thorough description on how to use the map right under the Map section of the website. It sufficiently documents the specific functions of the menu bar and the search feature, and shows the reader how to navigate throughout the map (zooming in/out, changing layers, inserting more maps etc). There are symbols on the map that show various hospitals, churches, petition events and houses/apartments of renowned people at that time. One can also change map layers, which essentially gives the reader the option to either use a Washington map made during the Civil War or a contemporary DC map for the purpose of their research.
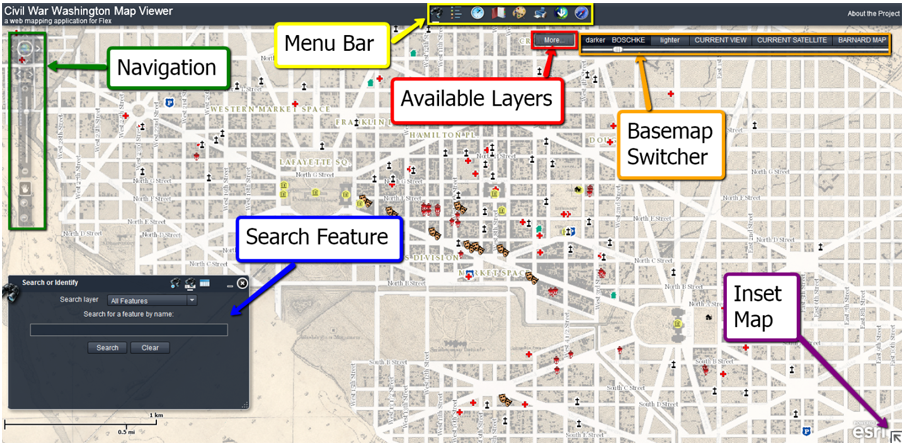
Part of the Visual Tutorial of the Map of in the Project.
A downside of the project might be that the website only includes traditional media expression tools like tables and pictures, but fails to incorporate more contemporary media formats, such as videos, plots, or mathematical charts. Granted, the project encompasses an online map that can be manipulated to a vast extent (described above), but those “traditional scholarly gestures” (Mattern n.d.) still far outweigh modern media formats. Therefore, adding more of said media would greatly increase the value, gravity and reliability of the information presented.
The data in this DH project is very much contextualized. Every piece of data, when opened, is automatically related to another most relevant data piece. This is most evident in the Data section. If the reader searches for a specific person, he will immediately be informed about the places, organization and events related to that person. The most relevant information is often provided in URL links to give the reader the opportunity to do further research on that aspect. Clicking on the “Abbott Thomas” link in the People section, for instance, the reader will be furnished with the most relevant information such as gender (male), race (European American), occupation (clerk), status (independent free) as well as places (1st Division Hospital) and organizations (101st New York Infantry) related to Thomas. These interconnections of data reflect to a certain extent that the participants of the project made controlled and deliberate decisions of the technology (in this case the website and URLs) they were using and also tells us that the information presented is not fabricated but strongly related to the context of the Civil War.

Interconnection of People, Organizations and Places in the Project.
Furthermore, the project itself has an “About” page and a FAQ section which document how the participants in this project created the website, how research into the subject matter was funded and what educational institutions were mainly contributing to the research and documentation of the data in the project. The web page creators have also paid meticulous attention to separating these kinds of information (About, FAQ, Participants etc.) from the actual research documentation (People Events, Organizations of DC during the Civil War) by putting the links of the former at the lowest part of the web page with a different background color, clearly separating the two parts.
Almost all of the participants that contributed to the formation of this project are consultants, research associates and research assistants, with only minor numbers of graduate students and no undergraduate students. It is regrettable that this project did not employ more student participation, however this doesn’t mean that the historical information provided by the project is only targeted for a strictly professional audience. In fact, kudos should be given to the creators for attempting to address one of the most important events in US history with documentations that are not only accessible to professional scholars, but also easily readable by a wide audience, including students and even amateurs. Additionally, the whole project is a good model for future project directors to refer to when developing their own project.
Last but not least, the project gives credit where credit is due. Every citation is appropriate and contains several URLs to the source where the information was gleaned. Credits and full descriptions of all the collaborators are also presented in the “Participants” section of the website. The website link www.civilwardc.org itself is an extremely straightforward link and provides other authors easier ways of citing the materials presented in the project.
In conclusion, I believe that the project is well established, sufficiently researched and annotated and shows numerous signs of the authors exercising control over their web page technologies. The project will surely stand out if those minor drawbacks mentioned above can be amended and remodeled.
Sources:
[1] Mattern Shannon C..Evaluating Multimodal Work, Revisited.
http://journalofdigitalhumanities.org/1-4/evaluating-multimodal-work-revisited-by-shannon-mattern/
Hi All,
PHD Comics recently included a short Youtube video about Distant Reading as part of a series of videos in which they ask graduate students to explain their thesis in two minutes. If you’re interested, you can check out the video here.
Copyright © 2024 All rights reserved.
Designed by 