Here it is!
http://www.longestpoemintheworld.com/

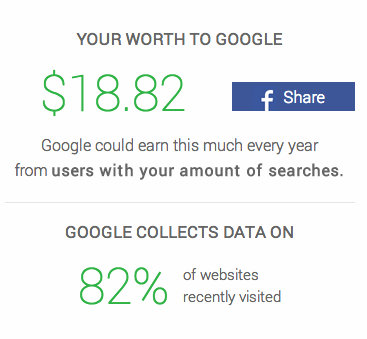
A medium that is able to analyze the thoughts you put out into the world constitutes as data tracking. Sometimes this is beneficial. By tracking the data of individuals, the government is able to track down the mood of the nation. Also, it is able to find individuals who are planning to threaten the peace. But because data can be utilized to threaten society, privacy rights where established in an attempt to set boundaries and diminish problems. Then, through the development of various programs, data reading applications were born. These apps such as PrivacyFix, Wolfram, and Tweet Report, synthesize our data in order to show us our Internet footprint. These types of apps are quantified as data tracking due to their nature of grasping our information and regurgitating it back to us in more simplistic forms. Regardless of whether this sounds creepy or not, we allowed them to go into our history in order to bring back to our present the data trends we put out into the internet. In retrospect, this can be considered type of way humans think alongside technology, since without our help, technology wouldn’t have had the ability to create this. In other words, technology needs us as much as we need technology. Through these types of experiences we are able to see on a broader perspective, how we present ourselves to the world through the Internet. A great example is the amount Privacy Fix calculates in order to show us how much we are worth to companies like Facebook. Clearly, such companies are making revenue from our activity, but we as well benefit from their functions. Those 18 dollars Facebook makes through my activity may seem insignificant, but considering they possess a large audience, it is clear how it became a multimillion-dollar company. Thinking about the way we affect data and how data affects us provides us with more awareness of the way we affect this multidimensional cyberspace filled with an almost infinite amount of information.
What does ancient oral storytelling have in common with cloud computing data centers? The connection lies in the fact that information cannot exist without a medium to store and deliver it. Before the invention of writing, human memory was the primary medium for storing information. Stories were passed down through oral traditions, yet these stories were constantly modified and warped as they were passed down, as imperfections in the medium strongly influenced the information. Information was lost whenever a story was told for the last time. The invention and growth of writing revolutionized the way that information was stored, allowing people much greater access (writings of a long-dead author, letters from far away relatives, current events, etc.). Writing increased the lifespan of information, although it was still very possible to lose data – history has seen far too many book burnings.
The advent of computing has brought about another information revolution, but it is important to remember that this data is still bound to physical media. In “A Material History of Bits,” Jean Francois Blanchette argues that bits “cannot escape the material constraints of the physical devices that manipulate, store, and exchange them” (1). Blanchette goes on to describe the mechanisms and processes that are used to store computer data. These mechanisms have again increased the lifespan of information – when information is lost on one system, often it can be recovered through another system. When most people log into Facebook or type in a Google search, they do not consider all of the physical computing systems that are involved in the process of bringing up the webpage on the screen. But the truth is that computing data is very much anchored to physical materials.
Consider a data apocalypse, where every single computer storage system in the world was destroyed (all bits reset to zero). It might seem intuitive that the information would still be floating around somewhere in vague immaterial space (as many people imagine the “cloud”), and that once the computer systems were rebuilt they would be able to dive back into the pool of information. However, if every computer storage system were emptied, then there would be no backups or other way of reclaiming the information. The reality is that once unanchored, the information would drift away like a balloon escaping from a child’s hand, never to be recovered.
Works Cited
Blanchette, Jean-Francois. “A Material History of Bits.” Web. 10 Oct. 2014.http://polaris.gseis.ucla.edu/blanchette/papers/materiality.pdf
I am worth $36 and change to Google. In order to be worth something, that means Google sells me or something I do to others. I am still here, in full ownership of myself—so Google sells something I do, and specifically, things that I do on Google and its partner websites. All of my searches, all of the websites I visit, everything I do through Google is data which the company can use and sell to other businesses for profit; therein lies my monetary value. But what does that mean, “sell my data?” Does Google have my entire history stored somewhere which it can then sell for a nickel a pop? Or does Google sell my privacy rights to other companies, who can then track what I do? I’m not confused about the ability to sell data. I assume it can’t be too hard to track what type of music I listen to, what kind of foods I like, what websites I visit, whatever, based on my internet searches. After all, the first place I go with any question is Google. I’m just wondering about how Google and other companies can put a value on my data, and what that means for data itself. The whole concept of buying and selling revolves around the notion of giving money in exchange for goods and services. Data is definitely not a service. I guess it is something that is produced and consumed, so therefore it could be classified as a good. I suppose that would be its medium as well—a consumer good. In terms of writing, reading and thinking I’m not so sure. I feel like if it is to have a role in these three areas, it would be in thinking, and not human analysis but rather data processing—kind of the way a computer program makes a computer “think” about certain data sets. In that sense data would be more like facts or input values, which can then be manipulated and modified to extract information. It really is fascinating that this is so relevant a topic that there are discussions about it, and enough of a discussion that me, with my $36 net worth, can contribute to them.

Stephan Thiel’s “Understanding Shakespeare” project succeeds as a digital design project, but it falls slightly short when viewed as a digital humanities project (which, in our opinion, requires effective analysis and original conclusions). Thiel aims to present a “new form of reading drama” (Thiel) to add new insights to Shakespeare’s works through information visualization. The project is broken into five separate approaches, each of which turns the words and events of Shakespearean drama into data and then presents said data in an informative visual display. While Thiel’s intentions (the “new form” stated above) constitute a worthy design goal, they do not serve as a strong thesis to guide the literary implications of his project (or lack thereof – literary conclusions are mostly absent). The separate approaches are not linked to support a core argument.
Each approach display has a small, concise description of its purpose, and presents data in a visual form that is easy for any average reader to navigate and explore. In viewing Shakespeare’s words as information to be processed (by methods described further on), Thiel goes against the opinions of Stephen Marche and others who argue that “literature is not data” (Marche). Marche fears the advent of the digital humanities and criticizes the field for being “nothing more than being vaguely in touch with technological reality” (Marche). He goes on to describe the sorts of algorithms that Thiel uses as “inherently fascistic” (Marche). Most digital humanities scholars will dismiss Marche’s fears of algorithms as irrational and exaggerated. However, there is a danger to the scholarly pursuit of literary analysis when projects claim to serve a literary purpose but instead do relatively little literary research. Although Thiel’s project is primarily a design project, his own self-written goals are a little too ambitious and reflect literary intentions that he does not satisfy. For example, his “Shakespeare Summarized” approach uses a word frequency algorithm to condense speeches from a play into one “most representative sentence” each, which he claims will create a “surprisingly insightful way to ‘read’ a play in less than a minute” (Thiel). This is a far-fetched claim, as the “Shakespeare Summarized” charts each turn out to be more of a disjointed collection of hit-or-miss quotes rather than a coherent narrative. The charts give no detail with regards to plot events or characters, and viewing this data cannot be compared to the experience of reading Shakespeare’s full prose. The data presented is of little value to someone who has not previously read the associated work. Therefore, Thiel falls short in re-purposing the data to create an analytic digital humanities project – instead, he simply gathers the data and presents it visually.
Another of the approaches, “Me, You and Them” (Thiel), serves to identify each character’s role by compiling statements that begin with personal pronouns. Thiel claims that this approach “reveals the goals and thoughts of each character” (Thiel), though the project itself does no analysis of the data. Scholars who are familiar with the work may be able to examine Thiel’s compiled data and draw conclusions from it, but there are no conclusions put forth as part of the project.
Looking at the overall project’s design and technique criteria, it is clear that this digital humanities project really did form in sync with the concept and tool application. Thiel is well aware of the affordances of his tools (the capabilities of each algorithm for useful visualization), and he is effective in organizing the data in a readable manner. The approach titled “Visualizing the Dramatic Structure” introduces Shakespeare’s plays through a fragmented lens. Each lens signifies a major character within the entire play, or simply a character important within one scene. To produce this, while still maintaining an authentic feel to reading a play, this approach has a very inventive page structure. The structure follows that of a novel, however the story is divided by vertical lines that create horizontal portions for each scene/character that summarize their most important lines. This format reveals how this approach properly demonstrates the affordances of the overall project through this particular fragmented, yet organized, display. Thiel focuses on using technology that affords him the ability to examine the scope of an entire story by highlighting smaller, important details. The only major concern or flaw in the design of the media was that the visuals were presented through Flickr. This made it somewhat difficult to zoom in far enough and more so to navigate the vertical Flickr photo. A higher resolution and different media type for the visuals would have pushed the design to a higher level of sophistication.

(Hamlet, Prince of Denmark – Understanding Shakespeare Project)
It is not sufficient to only view the final presentation of a digital humanities project. Examining the development of any project is imperative to fully appreciating the level of work and rigor involved within a project’s creation. Studying the design process also can reveal biases or assumptions inherent in the project. The “Understanding Shakespeare” project was successful in recording and documenting the entire process, from the digitalization of the plays, to the coding manipulation of the data, to its fruition. The process is presented through a series of Youtube videos fast-forwarding through the various mini-projects. This is a great tool to observe and, to an extent, understand the coding algorithms that were used to organize the words or lines of the play by frequency. The major dilemma with this entire process, however, is that without a Computer Science major, it may be impossible to understand the process of the coding by looking at the video. What is missing in this page is verbal dialogue, walking someone through the process as the video is playing. Therefore, even though the documentation is there, the transparency of the project’s development isn’t present.
This Shakespeare project not only documents the entire process to the final product, but it also thoroughly credits the different platforms and software used within the project. In the “About” tab, all the acknowledgements are made. It certifies that the data being used was based from the WordHoard Project and Northwestern University. In addition, it reveals that the software processors called “Toxicilbs” and “Classifer4J”, were the ones used to manipulate the data into an interesting visual arrangement based on frequency. In terms of project visibility, the open web accessibility of this project allows for any academic scholars to examine Thiel’s charts. Furthermore, it is also open and simple enough that it accommodates for the layman who may only be attracted to the visuals of one play that he or she may have read. It is worth noting, however, that Thiel does not make the raw data available to the public – he only displays the data visualizations.
To sum up “Understanding Shakespeare” as a digital humanities project, it helps to look through the lens of a prominent digital humanities scholar like Katherine Hayles. In her book “How We Think”, Hayles describes how “machine reading” processes like Thiel’s algorithms could supplement traditional reading experiences by providing a “first pass towards making visible patterns that human reading could then interpret” (Hayles 29). However, this relationship implies that machine reading could inform readers who have not yet read the work traditionally, and in the case of “Understanding Shakespeare”, the data is not of much use without previous familiarity with the drama. As of yet, no scholars have taken advantage of Thiel’s project to make literary arguments, and thus it still sits idly as what Mattern would describe as a “cool data set” (Mattern). Standing alone as data, the project leaves lingering questions: Could these techniques be applied effectively to the works of other authors, and more importantly, what are the literary implications of this type of data?
Citations:
Hayles, Katherine. How We Think: Digital Media and Contemporary Technogenesis. Chicago: U of Chicago, 2012. Web.
Marche, Stephen. “Literature Is Not Data: Against Digital Humanities – The Los…” The Los Angeles Review of Books. N.p., 28 Oct. 2012. Web. 15 Sept. 2014. <http://lareviewofbooks.org/essay/literature-is-not-data-against-digital-humanities/>.
Mattern, Shannon. “Evaluating Multimodal Work, Revisited.” » Journal of Digital Humanities. Journal of Digital Humanities, Fall 2012. Web. 22 Sept. 2014.
Thiel, Stephan. “Understanding Shakespeare.” Understanding Shakespeare. 2010. Web. <http://www.understanding-shakespeare.com/>.
After reading this week’s texts, I can see the augmentation potential in Digital Humanities. I envision a two-step revolution. The first stage was the gathering of text from these millions of traditionally printed works. A perfect example of this was Larry Page’s project to digitalize books and use a “crowd-sourced textual correction… program called reCAPTCHA” (Marche). This revolutionary step definitely attracted criticism and as a relatively new concept, the direction of digital humanities and language-analyzing algorithms was uncertain. A major part of this active debate is whether literature is data. Some critics suggest, “Literature is the opposite of data. The first problem is that literature is terminally incomplete” (Marche). Another perfectly acceptable argument is that, “the [text] data are exactly identical; their meanings are completely separate” (Marche). I can agree with these criticisms regarding the limitations of the digitalization of text. However, I also think that these arguments will become absolute within the next decade, if not sooner.
Looking at developing projects based on coding algorithms to analyze text, the augmentation of analysis is present. Through the digital humanities, one is able to grasp patterns in millions of words or “data”, and learn something from it. One example is the interactive visual representation of the most used words in the State of Union address for each year, starting from George Washington to Barack Obama. This effective augmentation of scholarship is not only exposed to academic community, but to the entire general population in the United States. The ability to analysis hundreds of speeches at a macro-level within a few minutes simply could not have been done without the digitalization of text. This tool is just the tip of the iceberg, as the second step to Digital Humanities is just beginning.
This second step will close the gap between raw data and literature with meaning. The use of deep learning techniques through the use of coding algorithms is the direction in which digital humanities is going. Google is spearheading a “deep-learning software designed to understand the relationships between words with no human guidance” (Harris). This open sourced tool called word2vec is a movement that will push the analysis of text through computers to new levels. This future movement refers back to Hayles’, How We Think, because it will only be a matter of time before the distinctions between “machine reading” and human interpretation will be unnoticeable (Hayles 29).
Gibson, William. Neuromancer. New York: Ace, 1984. Print.
Harris, Derrick. “We’re on the Cusp of Deep Learning for the Masses. You Can Thank Google Later.” Gigaom. Gigaom, Inc., 16 Aug. 2014. Web. 12 Sept. 2014. <https://gigaom.com/2013/08/16/were-on-the-cusp-of-deep-learning-for-the-masses-you-can-thank-google-later/>.
Hayles, Katherine. How We Think: Digital Media and Contemporary Technogenesis. Chicago: U of Chicago, 2012. Print.
Hom, Daniel. “State of the Union, in Words.” Business Intelligence and Analytics. Tableau, 12 Feb. 2013. Web. 12 Sept. 2014. <http://www.tableausoftware.com/public/blog/2013/02/state-union-words-1818>.
Marche, Stephen. “Literature Is Not Data: Against Digital Humanities – The Los…” The Los Angeles Review of Books. N.p., 28 Oct. 2012. Web. 15 Sept. 2014. <http://lareviewofbooks.org/essay/literature-is-not-data-against-digital-humanities/>.
Powered by WordPress & Theme by Anders Norén