
Project Summary
Who should get to decide what a utopian society looks like? After London was razed to the ground in the Great Fire of 1666, its reconstruction into the “emerald gem of Europe” was heavily influenced by the monarchy and aristocratic elites. In building a utopian epicenter focused on political and economic interests, immense sacrifices had to be made by London’s most marginalized citizens. A team of students led by Nicholas Smolenski (Ph.D. Candidate, Musicology) and Dr. Astrid Giugni (Lecturing Fellow, English) will thus explore how London was rebuilt into a utopia; by employing topic modeling and applying the resulting lexicon to seventeenth-century architectural sketches, students will demonstrate how a language of progress became inextricably linked to its own image while also exposing the paradoxes entrenched in utopic representation. This project will additionally show how its framework can apply to current political discourse, as the tearing down of statues and monuments over the past three years has highlighted inescapable tensions between a governing power, a nation’s history, and its people.
About the Database
We used text from EEBO-TCP Database. We filtered out 1600-1700 text using the teir2r package. To address spelling variation in Early English Printed Book, the project utilized VARD 2.0. We applied a 50% threshold for all text.
From tracking the average type/token count, we discover that pre-1650 (English civil war) displayed a higher type/token count compared to post-1650. Political instability causes a decrease in book publication and the return of monarchy causes an increase in the book trade.
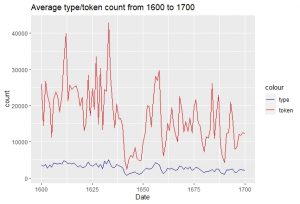
Figure 1: average count of type and token, 1600 – 1700
Exploratory Analysis also displays certain limitations of the EEBO-TCP Database.
- As we can see from figure 2, texts from EEBO-TCP Database are predominately long. We mostly analyze books and pamphlets instead of poetry, which might cause bias in our model.
- Token count increase with Type count, which displays a linear relationship. As a result, lexical richness is correlated with text genre/length.
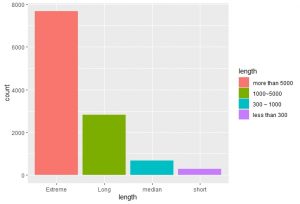
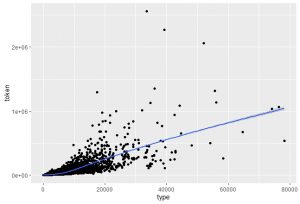
Figure 2: distribution of text length in EEBO Database Figure 3: the relationship between type and token