Introduction
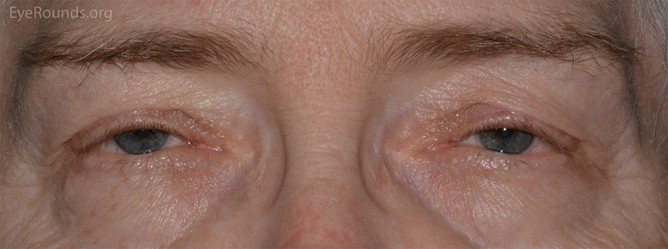
It is well known that as the human body ages some of its functions degrade. On of the main effects of age is the loss of function in the five senses. For sight, this could appear in the form of age-related macular degeneration or the loss of eyelid function resulting in ptosis (colloquially known as “droopy eyelid”). There are several types of ptosis (acquired, congenital, myogenic) but the most common type is acquired ptosis. In a study by Cynthia Matossian, 94 patients aged 50 years or older who scheduled an eye clinic appointment for any reason and had 188 eyes analyzed [1] . Overall, 73.4% of patients had ptosis in at least one eye, and 25.5% had an asymmetric upper eyelid presentation.

Muscles Relevant to Eyelid Function
To assess the severity of ptosis in their patients, osteoplastic surgeons must take certain measurements of the patient’s eye and eyelid. Currently, these measurements are performed manually with a ruler or on static photographs, which introduces variability. Our team is seeking to develop a phone/tablet application that can be used by oculoplastic surgeons for the clinical evaluation of ptosis (colloquially known as “droopy eyelid.”). The application will provide physicians with a standardized, reproducible method and tool to assess eyelid function, which is crucial for diagnosis and determining surgical candidacy.
Problem Statement
Relevant Terms
Design Methodology
The design methodology for this project can be split into three areas: Computer Vision and Machine Learning (ML), App Development, and Physical Testing Device. A mind map for each of these subsystems, as well as the user experience, was created to organize the priorities to consider in the design of each subsystem. A description of specifications for each subsystem is found below.




Research and Education Problem
Computer Vision and Machine Learning
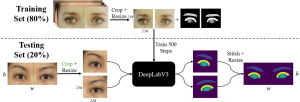
The datasets used for training the ML algorithm was the Chicago Facial Dataset (CFD) and the CelebAMask-HQ (Celeb) dataset, which had 827 and 2015 images, respectively. For the generation of the anatomical masks, five annotators were trained to use the Computer Vision Annotation Tool (CVAT) to draw masks which indicated the iris, sclera, lids, caruncles, and brows. The intragrader and intergrader validation was conducted by having each grader annotate an additional 100 images (60 from Celeb and 40 from CFD), and a minimum of 2-weeks elapsed from the time of initial annotation to allow for intragrader evaluation over time (Nahass, et al.). From theses tests, a Dice Score was calculated to determine the robustness of the data generated. The segmentation models are a DeepLabV3 segmentation network with a ResNet-101 backbone that was pretrained on ImageNet1K from Torchvision. Prior to training and prediction, the input images were split in half and resized to 256 x 256. This similar method was applied to testing, and at the end the segmentation maps are recombined using the same aspect ratio as the initial image. Then the Dice Scores were calculated using the recombined image and original segmentation masks to evaluate model performance.
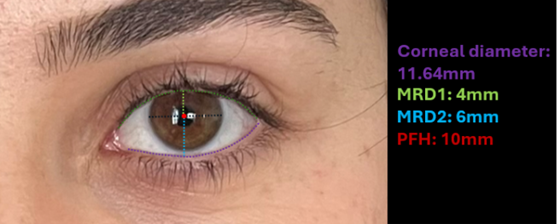
For the prediction of distances, the human annotated segmentation masks provide a benchmark for the results of the ML algorithm predicted results. As for the external reference of distance, we used the iris diameter denoted as 11.71 mm, which was used to convert a pixel count to millimeter distance. MRD1 and MRD2 were calculated from the distance from the center of the iris to the upper and lower eyelids, respectively. Then the palpebral fissure height (PFH), which is defined as MRD1 + MRD2, was calculated by adding these two values together for each eye. For our current proof-of-concept prototype we only show the calculation for MRD1, MRD2, and PFH; however, the ML algorithm can calculate amount of iris shown, inner and outer canthal distance, interpupillary distance, brow heights, canthal tilt, canthal height, vertical dystopia, and horizontal palpebral fissure.


App Development
At first, an AI app builder was considered to quickly iterate through different user interface (UI) designs, but a platform called FlutterFlow was found as good platform to build the app before pursuing this first idea. FlutterFlow is based in the Flutter coding language, which is commonly used to build both Android and IOS apps. In addition, it is low code, initiative and has access to easy cloud connection for both linking to an external server where the code would be hosted and storing user data on Google’s Firebase. This allowed more focus to be placed on making the developing the UI quickly and comprehensively.
![]()
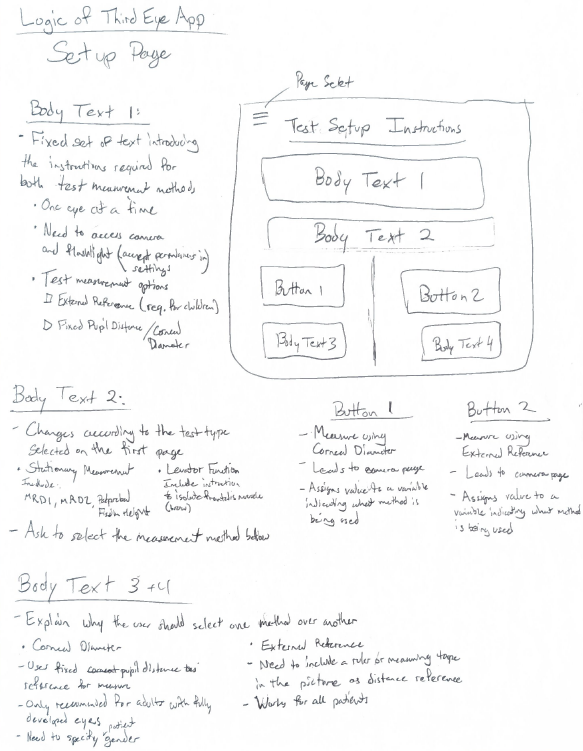
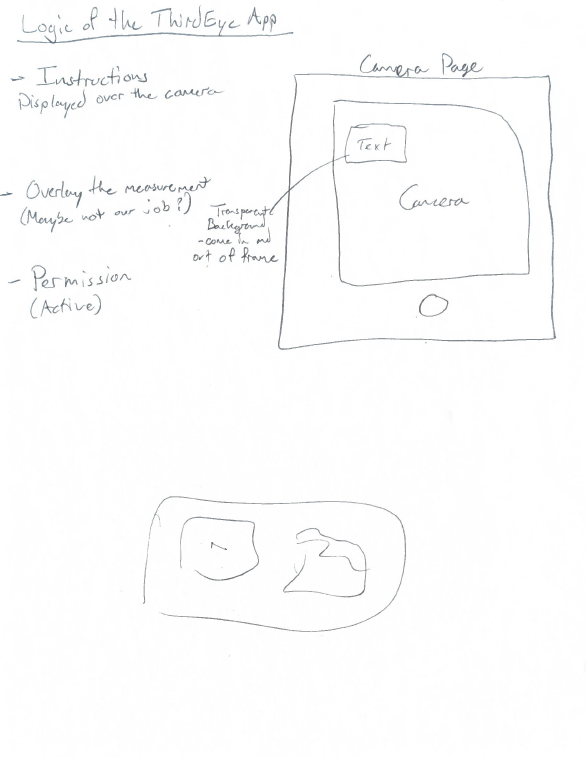
Before starting the code, a prototype of what some of the major pages in the app should look like were hand drawn on paper. This was to define the layout for each page, the logic of the user experience, and define what functionalities each page would require. Once done, app development began by recreating these layouts to learn the platform. Firebase was connected to this app as our means of data storage and filtering for each user. The first pages completed were the Homepage, Test Setup page, Image Gallery, Image display page, and camera page. These formed the core functionality of our app but later it became necessary to add more pages to better improve the user experience and increase the security of the app. These included a login and signup page, subject information page, and another image display page. The prototype for the Homepage is provided in the image below. All prototype pages will be provided in the appendix.

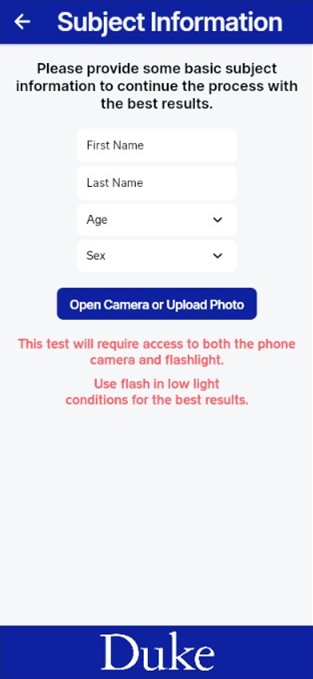
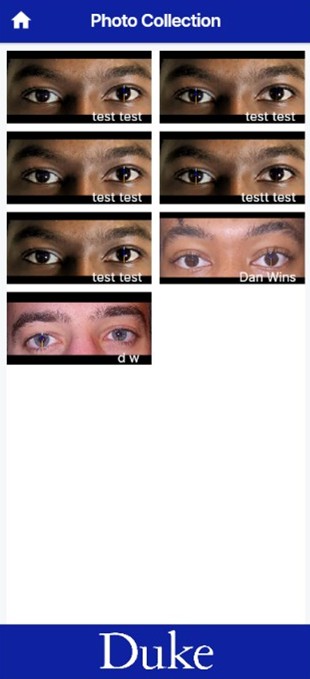
The expected user experience is defined as the following. On opening the app, the user is first directed to sign into their account or make an account, so that they can only access the pictures they have taken. After logging in they are directed to the Homepage, where they are given the choice of selecting which test they would prefer to conduct. Either Stationary eye measurements, where MRD1+2 and PFH are found for both eyes, or Levator Excursion, not yet available in the app due to or focus on building the eye measurement model first. After selecting one, they are taken to a test setup page that explains what each test is and asks for the preferred reference measurement. A choice is given between using a standard corneal diameter or external reference, like a ruler. Currently, only corneal diameter is built into the model. Then, the user is expected to provide some basic information on the subject they are taking for later sorting and easier data retrieval. Only the first and last name of the patient is required, but age and sex can also be provided. Next, the choice is given to upload a previous photo or take a live image as an input for the model. In both scenarios, the image should include the subject’s full face, taken about one foot away from the face with only one person in frame. Both front and back facing cameras are permissible. Once uploaded, the image is sent to an external server when the model is hosted for processing, and the output is returned to the app via an API call. From our testing with different hardware, this takes between 10 and 30 seconds to complete depending on the processing power of the device. Once processed, the image overlayed with annotations is displayed along with the calculated distances, and the option is available to retake the photo if the user is not satisfied with the results or to save the image for storage. Once saved, the user is directed to the photo gallery where they can click to view their saved images with the associated measurements. Screenshots of these app pages are provided in the appendix below. Once the app was sufficiently developed, preliminary testing could be conducted.
Testing was conducted in three ways: web-based testing built into Flutterflow, live testing the app using the Android emulator Android Studio, and testing on a real device. The web-based testing was most useful for early development to test changes without having to download any additional software. However, it is slow to load and did not provide adequate error messages of an error occurred. For these reasons, testing on an emulator was preferred to web-based testing. Using Android Studio, the app could be run on an emulated Android phone live on the computer. This introduced the live update feature where the app could be updated instantly with new changes instead of rebooting each time. It also provided full error messages and access to the computer’s webcam so live photos could start to be input into the model. This revealed that the dataset used was insufficient can could only handle the pre-segmented eye images that it was trained on. This was the preferred testing method, at the cost of only a few hours to setup, until it broke unexpectedly and could not be repaired in time. At this point however, web-based testing was used once again until testing on a real device was available.
Two strategies to connect the NN model to the app were tried in parallel. First, the model was tried to be implemented locally in the app, such that the user’s information would be more secure and possibly load results quicker. However, this presented too many problems to implement within the given timeframe. Instead, having an external server host the model and making an API call to that server to run the model as requested was the preferred method. This may be open to more security risks, but would be sufficient for the purposes of this project, where no sensitive data is yet being collected. Additionally, APIs are the easiest way to allow Pytorch models to be accessed by external applications like Flutterflow, so this method looked very promising. After finalizing the Pytorch model discussed in the neural network section, a simple Python script designed to expose it through an API was created. In order to create this API, the Python web framework FastAPI was used. It is a package in Python that is capable of building APIs using standard python hints. In simple terms, it takes the basic functionality of a model and creates endpoints that can take requests (external inputs) and run them through the model’s logic to create an output. The server used was Uvicorn, a web server designed to run APIs that use a Python framework like FastAPI. The validity of this method was tested by running the model, API, and sever on a computer using Window’s PowerShell. The process took around 15 seconds and outputted the correct annotated picture. After testing and approving the validity of the method, all relevant files (model, server, Python script creating API) were added to a GitHub repository, which will be linked in the appendix. The repository was then connected to Render, a cloud platform that deploys web applications. After deployment, Render creates a public URL that allows anyone to access the API endpoint and input a picture to get an annotated picture back as an output. Flutterflow uses the public URL to do the same exact thing: make an API call to send an input picture to the endpoint, and then receive the output back on the app. After integrating the URL into the app, Flutterflow and the model are essentially linked, connecting the two subsystems together.
To test on a real device, the app was connected to the Google Play Store and setup as under the internal testing track. This allowed for only those designated as testers to access the app. Internal testing was conducted on three devices: A Samsung A10 provided by the Co-lab, our personal phones, and the Raspberry pi power phone we made (that will be further discussed in the next section. Each device provided a different pixel count and a different amount of processing power such that we knew how the app would look and how smoothly the app would run over a range of different options. Once the model was finalized and integrated into the app, even on the lowest processing power device, took less than 20 seconds to load. This means a user could reasonably open the app and get the information they need in under a minute.
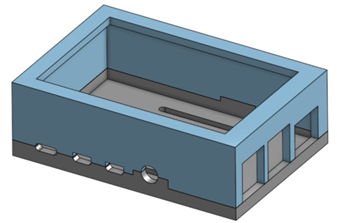
Physical Testing Device
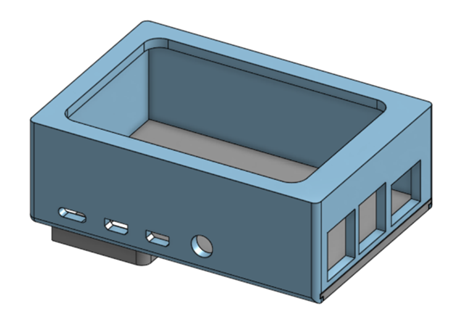
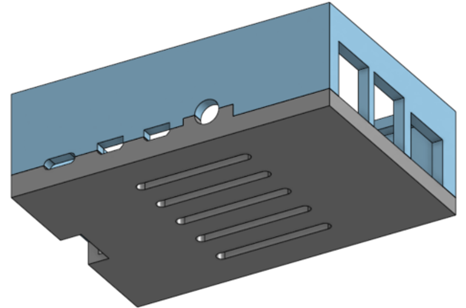
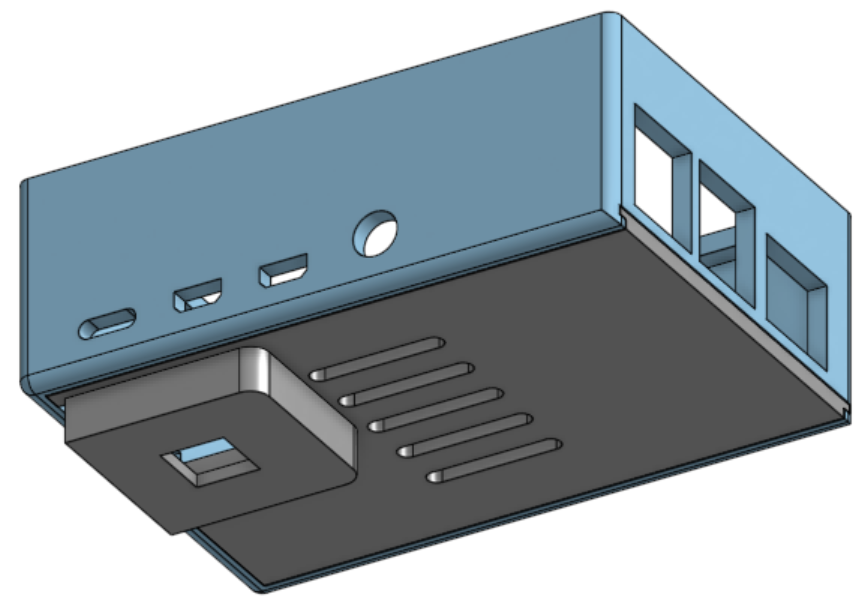

Conclusion and Future Work
Appendix