GitHub Repository of Code:
- ECBC-21-22/Code_Files main folder
- ECBC-21-22/embed.ipynb word embedding code
Word Embedding with Word2Vec:
Word embedding is a technique in natural language processing that transforms unique words in a given text document into mathematical vectors that encode different characteristics about the word through neural networks. To find semantically similar pairs of words, we examine cosine similarities, or the cosine angle between vectors, because closely associated words have vector encodings that are oriented similarly in space. The closer the cosine value is to 1, the smaller the angle between the vectors and more similar the words. The quintessential example of word embedding is that the algorithm can find that vector(“queen”) = vector(“king”) – vector(“man”) + vector(“woman”), or that “king” is to “man” as “queen” is to “woman” (Mikolov et al. 2).
We are using the Word2Vec continuous skip-gram model algorithm in the Python Gensim library to generate these embeddings and the Tensorflow Embedding Projector to visualize the results. The continuous skip-gram model predicts the context, or neighboring words, of a given term, while the continuous bag of words (CBOW) model predicts a word from the context. According to the experimentation results of Mikolov et al., the continuous skip-gram model performs better at predicting semantic relationships than the other Word2Vec model (continuous bag of words) even though it is more computationally complex, i.e., takes longer to train on the data (7). Because we are more interested in semantic rather than syntactic relationships, we have chosen to use the skip-gram model.
Our purpose is discovering words in our datasets that are similar in meaning to the different parts of speech and spelling variants of terms related to monopoly, consumption, and corruption, as well as various consumables from the East Indies that the EIC imported, e.g., calico, indigo, tea, and silk. If there are words with clearly negative connotations associated with the target term, then we know that the era-specific discourse of the term is likely to be disapproving. Moreover, the associated words offer insight into alternative names that writers may have used for a target term. While our conclusions about the influence of the EIC on England’s body politic will ultimately come from close readings of select texts, computational methods like word embedding can help us verify our claims about early modern writers’ ethical attitudes toward the trade practices and importations of the EIC in a large set of texts.
Our Methodology:
As with topic modeling, we did all our coding in Jupyter Notebook. First, we chose a CSV file of categorized texts to be our dataset. One such dataset is {publica_eic_monopoly}, defined to be the set of the 105 texts from 1660-1714 in EEBO-TCP that our topic modeling algorithm has classified to be publica and which contain mentions of both the EIC and monopoly in any spelling variation. See the Topic Modeling page for details on text categorization. After opening and reading the input file, we called the embed function, which first removes stopwords from the texts using the remove_stopwords function. Then, we trained a bigram detector on the text to create bigrams such as “body_politic,” which would then be vectorized just as the other individual words in the data. Finally, the function trains and saves a Word2Vec continuous skip-gram model of the dataset. We configured the model to only consider n-grams that occur at least five times. The last step is to convert the Word2Vec model into tab-separated values (TSV) files of vectors and metadata, respectively, using the tensor function so that we can feed the embeddings into Tensorflow’s embedding projector.
With our model built, we can then find the top ten similar words and bi-grams using the similar function, which calls Gensim’s built-in most_similar function to calculate the closest words in cosine angle distance. We can also find the cosine similarity between two words or bigrams using our comparePair function.
Results:
{publica_eic_monopoly}
For an interactive visualization of our most recent embedding, visit this projection of our {publica_eic_monopoly} data.
Here are some specific results from our most recent trial. Note that the algorithm is nondeterministic, so results vary each time. Moreover, the bigrams generated each time also differ. For example, “public_good” was a bigram that appeared in one early trial but did not appear again in subsequent trial runs. However, “monopoly_evils,” “body_politick,” and “body_politic” appeared every time.
Most similar words to “monopoly” and its variants in {publica_eic_monopoly}
- monopolies: laws_land freedom_trade retrained restrain restrained retrain exclude_others wrong legally privilege
- The most similar n-gram has cosine distance 0.9599364995956421
- monopoly: exclusive depending regulated_company joint_stocks monopolies retrained privilege wrong majeties_subjects allege
- The most similar n-gram has cosine distance 0.9274605512619019
- monopolise: allegations advantages_profits ingroed naturally_follow befalls free_encumbrances trengthen fact_allege corporation_excluding default_paying
- The most similar n-gram has cosine distance 0.9918798804283142
- monopolising: enriched greater_prices remote_parts riches_strength rates_exchange feel_effects encreaing increase_navigation increase_seamen attempting
- The most similar n-gram has cosine distance 0.9856666326522827
- monopolizers: lil vat_extent butchers served_apprentice tillage stil betowed consuming afford_gains trademan
- The most similar n-gram has cosine distance 0.991474449634552
- monopolised: olely forces_forts diffuive majeties_revenue solely extenive timely_prevented divided_amongt restraining diffusive
- The most similar n-gram has cosine distance 0.9849039316177368
Finding the cosine distance between pairs of words. These results were chosen to be presented here due to their high cosine similarity values. Find full results here
- Cosine similarity between body_politic and monopolies: 0.92482644
- Cosine similarity between body_politick and corrupting: 0.9881547
- Cosine similarity between body_politick and monopolise: 0.9774324
- Cosine similarity between public_utility and monopolise: 0.96104383
- Cosine similarity between public_affairs and monopolise: 0.94685894
- Cosine similarity between public_utility and corrupt: 0.9706364
- Cosine similarity between public_utility and corrupting: 0.9890693
- Cosine similarity between odious and monopolise: 0.92779535
- Cosine similarity between odious and monopolising: 0.9205425
- Cosine similarity between odious and monopolizers: 0.9433861
- Cosine similarity between repugnant and monopolise: 0.93447375
- Cosine similarity between repugnant and monopolizers: 0.92215055
- Cosine similarity between repugnant and monopolised: 0.91690487
- Cosine similarity between repugnant and corrupt: 0.9394476
- Cosine similarity between repugnant and corrupting: 0.9594015
- Cosine similarity between monopoly_evils and monopolise: 0.9452351
- Cosine similarity between monopoly_evils and monopolizers: 0.9702353
- Cosine similarity between monopoly_evils and corrupt: 0.97411305
- Cosine similarity between monopoly_evils and corrupting: 0.9790802
- Cosine similarity between arbitrary and corrupt: 0.86029494
- Cosine similarity between popery and corrupt: 0.82087946
- Cosine similarity between bribery and corrupt: 0.9573516
As we had expected, the set of words related to “monopoly” feature economic terms such as “joint_stock” and “commodities_imported” and references to its definition, e.g., “restrained,” “privilege,” and “exclusive.” However, we were surprised that “body_politic” appears so closely related to both “monopoly,” as “body_politic” is a manifestation of metaphorical medical language applied to view political affairs. This data tells us that the discussion of monopolies was intricately tied to analyses of English society and politics. The bigrams of “joint_stock” and “regulated_company” are very closely associated with “monopoly” because the EIC was a joint-stock company established by a royal charter and expanded by the investments of individual English merchants. Our research question is precisely how such “joint_stock” companies that “increase_navigation” affected England’s “body_politic.” Such results from word embedding reinforce the significance of our research question.
Notably, “monopoly_evils” is closely associated with “corruption.” The appending of “evils” onto “monopoly” suggests the idea that writers had not viewed a monopoly to be inherently wrong but rather subject to misuse by its participants.
In testing out the model, we also compared terms like “arbitrary” and “popery” to “corrupt” because public opinion in the Restoration was heavily wary of both arbitrary government in the form of Dutch republicanism and absolutism in the form of Catholicism. Indeed, we find that the degree of similarity is quite high, albeit not as high as the relationship of “bribery” to “corrupt.”
{publica_eic}
For a larger dataset, we created embeddings of {publica_eic} texts, which total to 454 texts and contain {publica_eic_monopoly}.
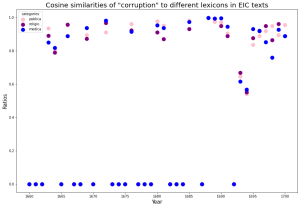

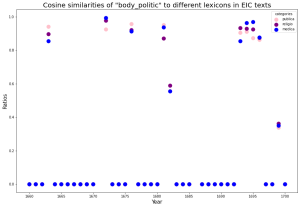
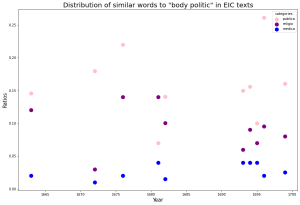
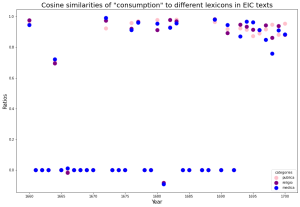

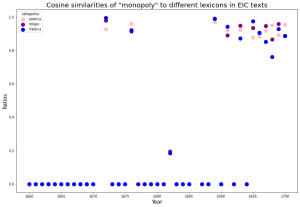

The scatter plots in the left column represent attempts to relate target terms to our three lexicons over time by taking the average of similarity scores between a term and each word within the lexicons if they occur within the same embedding of texts. We embedded texts from each year separately. For most years, there is no score–all three data points are at zero. The reason why medica is quite high in the graph for some of the years is that “corruption” and “consumption” themselves are in our medica lexicon. However, we did not expect that the averages of all occurring pairs of words across lexicons would be clustered together so often. We can tell that most years do not feature any discussion of the terms, but 1695-1700 contains the most hits.
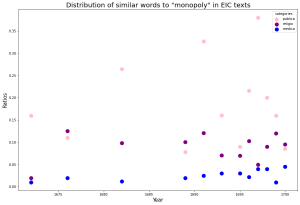
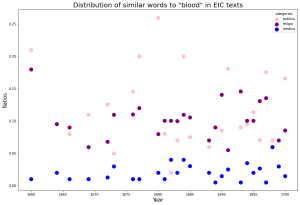
The column to the right shows the distribution of the hundred most similar words to each target term across the three lexicons. Despite the words being most present in the context of public affairs, they still retain some similarity with religious and medical terminology according to our results. There is the inherent limitation that our lexicons do not account for all the possible occurring words, so this only reflects those that we have already assigned to categories. “Corruption” starts off as more related to our religio lexicon but turns to publica starting in 1680. “Consumption” and “monopoly” are both more similar to publica terms. The data on “body politic” is more sparse, but publica is higher in ratio. Although the similarity analysis for “blood” shows that it is most associated with medica, we nonetheless find that more of its similar terms occur most in our publica lexicon. This methodology gives us insight on the scope of our lexicons, which were created by hand. One obvious next step is to expand these lexicons with the data generated in the embeddings.
Most similar words to our target terms in {publica_eic}
- monopolies: retraints freedom_trade erected_maintenance restraints patents_granted restrictions sole_buying lord_cook retrictions monopoly
- The most similar n-gram has cosine distance 0.8899826407432556
- monopoly: monopolies joynt_stocks reas joint_stocks excluding_others exclusive_others restraints regulated_companies participate freedom_trade
- The most similar n-gram has cosine distance 0.8507271409034729
- consumption: importations consumption_foreign consumed home_consumption thousand_packs greater_consumption consuming cloth_linen manufacturing native_product
- The most similar n-gram has cosine distance 0.8884536623954773
- consume: spent_home cheapest conume unmanufactured manufacturing consumption_foreign cheaply supply_materials deserve_esteemed greater_consumption
- The most similar n-gram has cosine distance 0.9185138940811157
- consuming: consumption_foreign conuming unmanufactured conumption_foreign native_product impoverish_manufacturers growths grograin_yarn deserve_esteemed cheaply
- The most similar n-gram has cosine distance 0.9450147151947021
- corruption: influenc health_infirmity task_masters utility simplicity_original treasure_artificial rhetoric unchangeable governable reasonableness
- The most similar n-gram has cosine distance 0.849184513092041
- corrupt: guided converation tempers challenges crafty moral_virtues heinous avowed doings falhood
- The most similar n-gram has cosine distance 0.9060556888580322
Again, the set of words related to “monopoly” feature economic terms and refer to the restrictive nature of monopolies. Consumption is associated with different sourcings of goods, home vs. foreign, because attitudes towards the two often favored the interests of one over the other. The words close to corruption are more ambiguous; there’s “health_infirmity” and “moral_virtues,” but also words like “guided” and “conversation” that are not so clear to interpret. However, the sorting procedure with topic modeling is not perfect, so there may be texts that are not as connected to trade or economics as other texts clearly are which can skew results.