GitHub Repository of Code:
- ECBC-21-22/Code_Files main folder
- ECBC-21-22/topics.ipynb topic modeling code
Latent Dirichlet Allocation (LDA):
LDA is a form of unsupervised probabilistic modeling method for uncovering underlying (“latent”) topics in a document without the aid of any pre-generated labels. This method groups words occurring within a Bag of Words model of the text into a specified number of topics represented as a cluster of words that each bear a term frequency percentage weight. As a reminder, the Bag of Words model removes all punctuation except those intrinsic to a word’s meaning (i.e., hyphens and apostrophes) from a given text. By ignoring syntax, a LDA algorithm can create a document term matrix containing frequencies of individual terms to then group into topics. For our investigation, we use LDA topic modeling both to help filter texts into categories and to discover topics in classified collections of texts.
Our Methodology:
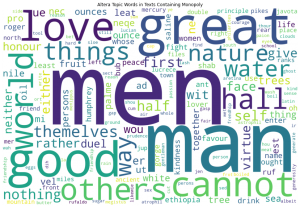
We devised four broad categories for classifying our Restoration-era texts. The first three involve lists of words, and the last is for all other texts. The publica lexicon relates to public affairs, including economic, political, and legal terminology. The religio lexicon includes any Biblical or strongly moralistic words. The Latin term “religio” carries the meanings of conscientiousness and moral obligation. The medica lexicon contains medical and physiological words. Our religio lexicon largely comes from the Data+ team’s religious lexicon with some additional revision. We produced the publica and medica lexicons based on close readings of early modern texts as well as discoveries from running the topic modeling algorithm. The altera category is for any texts that have no occurrences of topic words found in the three lexicons. It will be interesting to see what topics pop up here, since we do not have prior knowledge of them. The topic word cloud below shows words found in the altera category of texts that mention monopoly in our time period. None of the words in the cloud are in our lexicons.
We did topic modeling entirely in Python on Jupyter Notebook. First, we found all texts from the EEBO clean CSVs which dated within 1660-1714 and added them to a separate CSV file called restoration.csv in the filter.ipynb file. Although there are very few texts from 1701 onwards, we still included those 58 texts. Then, we filtered texts from restoration.csv that contain target words into separate files, such as eic.csv (484 texts), monopoly.csv (792 texts), and eic_monopoly.csv (87 texts). To catch as many occurrences as possible, we accounted for spelling variations by using re.search(…) with the different patterns we compiled together. Here are the patterns we used for the EIC and monopoly:
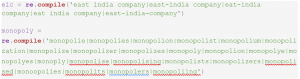
Again, as we explained before in the About Our Dataset page, we have to account for the missing “s” in the middle of words that could not be autocorrected effectively by a spelling normalizer. Strangely, many duplicate texts feature normal spelling in one version and “s”-lacking spelling in another.
The topicModel function is the main execution function. It takes a large CSV file with all relevant texts and then calls a series of other functions before copying individual texts into their new categorical dataframes. The function outputs a TXT file of topic words (one line per text) and a CSV file of the corresponding texts with all its identifying information.
We first converted each text from the CSV text column into a list of words and removed stop words from them using the remove_stopwords function. It was necessary for us to expand the standard NLTK stop words list with words we found in our first few test runs of the topic modeling algorithm. These new additions include era-specific adverbs, misspellings, and words that did not help distinguish the text into our categories.
The model function uses the Gensim library to create a LDA topic model for each text. Here is an example topic model created from an EIC text:
The title is listed at the top, and three topics follow with their index at the front and the topic words in the square brackets. We found that the words in different topics were often redundant, so we decided to only use the 10 words within the first topic as the distinguishing factors for each text.
Then, we used the sortByTopics function to calculate the relevant proportions of topic words that fall into our three lexical categories, publica, religio, and medica. The highest ratio determined the text’s classification, and texts with no lexical hits were sorted into the altera category. The save function writes each set of 10 words into an output TXT file within the appropriate folder. The following picture shows the medica topic words for EIC texts. Again, each line represents the words within the first and thus largest topic for one text. 
Sample of topic words in the publica category of eic_monopoly texts:

The one religio text in eic_monopoly.csv:

In the initial stages of experimentation, we reran the algorithm a few times to identify new words to add into our lexicons and stop words. The examine function helps us identify which topic words do not occur at all in our lexicons.
In the most recent run of the algorithm, the distribution of texts is as follows:
- Publica: 105; Religio: 1 for eic_monopoly.csv
- Publica: 454; Religio: 22; Medica: 3; Altera: 5 for eic.csv
- Publica: 499; Religio: 525; Medica: 27; Altera: 43 for monopoly.csv
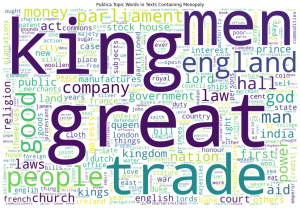
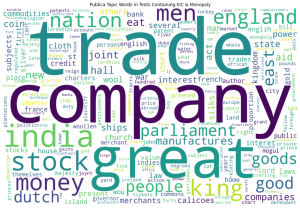
Once the topic filtering seemed to work sufficiently well, we visualized topic distributions within each subset of texts using word clouds. The following three word clouds represent the topic words found in the publica topic words category for eic_monopoly texts, EIC texts, and monopoly texts. In other words, the input file for each word cloud is the TXT file of topic words generated by the topicModel algorithm described above. The larger the size of a word, the more frequent the word appears in the input file. The results from publica eic are exactly as we expected, words relating to trade, company, stock, and even the Dutch, whose involvement in the East Indies trade preceded that of England’s. In the eic_monopoly set, “great” is not the largest topic and “company” appears just as large as “trade.” The density of words in these three clouds conveys the size of the dataset: the publica eic and publica monopoly sets contain much more texts than the publica eic_monopoly set. In the monopoly category, “men” and “king” are much more prominent than in the other two, and “trade” and “company” are both smaller, which may mean that the content may deal with certain governmental or official matters beyond economic exchange. One interesting question is to discover how “great” is used in early modern texts, as the word has occurred in large font in all of the word clouds we have looked at so far. From our word embedding results, we find that the word most associated with “great” in the publica eic_monopoly set is “tory_plot,” which further suggests that the term was used often in political contexts. Another next step is to look at the word cloud for EIC texts that do not contain monopoly for comparison with the eic_monopoly set.

With the texts sorted, we were also interested in the top 10 LDA topics (not the words within one topic) for all the combined texts in a category. We used the pyLDAvis library to visualize the 30 most salient topics in different categories of texts as a way to evaluate the effectiveness of our topic filtering algorithm. Here is the distribution of topic words for the publica eic_monopoly set:
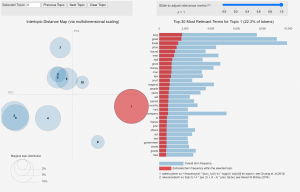
In the eic_monopoly case, the code was effective for sorting out the outlier religio text that mentions the EIC only at the beginning as part of the title of another text and mentions monopoly in a religious context to refer to those who are “Pretenders to, and Monopolizers of Saintship and Holiness.” For larger datasets, visualizing the topics using pyLDAvis is more effective for seeing whether the sorted texts truly do fall into its assigned category than manually looking through each text. Here is the visualization for the top ten topics occurring within the eic_monopoly texts classified as publica. Most of the terms are indeed related to public affairs, so this classification is effective.
With texts appropriately classified, looking at word frequencies, authorship, and publishers over time and across categories would be more meaningful than just looking at those data in an entire collection of texts.