In our period of focus, the Restoration Period of Europe, monopolies become an important concept. But what is discussed when the term “monopoly” is used? To begin to figure this out, we created word clouds for the common terms/words that appear in texts wherein “monopoly” or one of its other spellings and some form of “East India Company” are found, to serve as a basis for finding other relevant research directions.
A word cloud is a collection of the most common words in a text or set of texts, weighted by frequency. In this case, the more frequent words are larger. The code for this can be found on our GitHub.
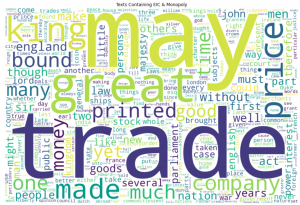
After searching through the files that contained both EIC and monopoly, we realized that, in the time period, the EIC may not have been referred to as a “monopoly,” so we looked into the texts which just contained “East India Company.” For example, monopoly was not one of the most frequent terms in these files, so it may not have been the most common term used to describe such a phenomenon.
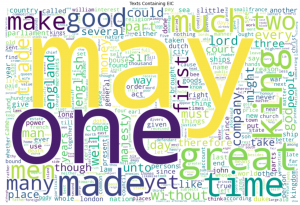
Many of the words in the word clouds make a lot of sense, given what we know about the EIC. Some words are a bit more puzzling. E.g., why is “may” such a common word—in fact, the most common word? Since the spellings were normalized and uncapitalized in the dataset in which we worked, we don’t know whether this refers to the month, or the verb.
Future directions could include word clouds of texts containing other words of interest. However, this is limited by the fact that more common words appear in vastly more texts, and lead to more general results that may not be as useful. After these introductory visualizations, we decided to move more towards topic modeling as a method of gleaning more information from the EEBO texts. Since the cleaned EEBO dataset is imperfect vis-à-vis spelling of words as they have changed over time, these visualizations must be taken with a heavy grain of salt.