Early English Books Online (EEBO) is a comprehensive database of early modern English texts dating from 1470 to 1700. Our dataset comes from EEBO-TCP, a collection of SGML/XML-encoded versions of EEBO texts that enable accessible searching. These files can be downloaded from here: FAQ – Text Creation Partnership.
In the summer of 2021, the Ethical Consumption Before Capitalism Data+ team downloaded and converted these XML files to CSV files: Data+ Clean CSV Texts. Here is an example file:

In the text cleaning process, the Data+ team chose a bag-of-words model, which transforms a text into a “bag” or set of words that discards syntax and grammar but preserves the original multiplicity of each word. Thus, they removed all punctuation marks except hyphens and apostrophes and made all letters lower case. Although we have continued using the clean CSV files, we may want to examine texts that preserve punctuation and capitalization in future investigations. For example, “may” is one of the most frequent words in the entire dataset, but we do not know whether it is used most as the month or the verb.
Moreover, the Data+ team normalized the spellings at a threshold of 40 percent using VARD, a spelling normalization software for early texts that makes word replacements by calculating the number of edits required to change a word into its modern spelling. The rationale of setting a low threshold is to allow the software to automatically make corrections, which requires it to calculate a confidence score greater than the threshold. However, certain texts still feature abnormalities in spelling, such as the loss of “s” in words–a feature that may result from the use of long “s” character in early texts. When trying to correct those abnormalities further, we noticed a lack of effectiveness. For example, “publihed” became “pebbled” during one of our tries with the software. We have dealt with this problem by adding those variants lacking “s” into our lexicons for text classification. See the topic modeling page for details on how we filtered the texts into categories.
For more context, here is a graph of the dated publications in EEBO-TCP: 
In our team’s target research period (1660-1714), the following graph shows the distribution of publications. Note that the number of books drastically plummet in the early 1660s due to the Licensing of the Press Act of 1662, a censorship law under Charles II that required books to be licensed before being printed (Nipps, 2014). Unfortunately, EEBO does not contain many texts from the 18th century, which limits the computational exploration of the early 18th century (1700-1714) in our overall exploration.

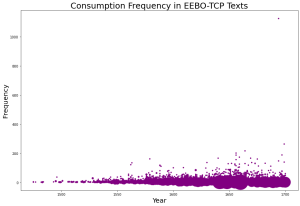
For a comprehensive overview, we examined the frequencies of our target terms in all of the files which the Data+ team processed from EEBO-TCP. We accounted for as many spelling variations as we could. The frequency of these terms increased significantly after the mid-17th century, coinciding with the political and religious crises of the time. Significantly, there was an explosion of attention on “corruption” in the mid-17th century. While the occurrences of the terms in individual documents are generally low, they are present in large densities of texts in our time period.