DATA COLLECTION FROM EEBO AND PRELIMINARY FORMATTING:
Since Gephi requires a very specific format for processing data to form social networks, the first step to assembling that data for Gephi is gathering it in the first place. The approach our group used was to target specific publishers, authors, and printers that interested us in London’s 17th century burgeoning publishing industry. We used the ProQuest platform of Early English Books Online (EEBO) to do this. For each person that interested us, we first compiled a spreadsheet of all of their available works on EEBO. Searches of author, publisher, or printer names yielded results like these on EEBO:
Our spreadsheet was formatted with the basic headings seen below. Included in this image are some example entries of texts found in EEBO:
For the aforementioned search in EEBO of Euthymiae Raptus, the corresponding preliminary spreadsheet representation would be this image:
Humphrey Lownes is the full name of the H.L. that this work was “Printed by”. Thus, Humphrey Lownes was marked down as the printer for this work. Since the EEBO report said that Lownes printed it for “Rich. Bonian and H. Walley,” those two are listed as being the publishers of this piece. In the additional information category, the location of their shop is listed so that we could begin to keep track of corresponding geographic locations to certain publishers and or booksellers. The category “Partnership” is blank since Chapman did not have a coauthor or co-translator on this specific work.
We repeated this process using what was available on EEBO to compile preliminary spreadsheets for the following publishers, printers, and authors: Thomas Dekker, Nathaniel Butter, Thomas Middleton, John Marston, Francis Beaumount, Nicholas Okes, George Chapman, and Ben Jonson. Duplicate entries were not put down for works unless they were published in separate years or with a different set of publishers and printers.
CODE FOR GEPHI PROCESSING
Gephi requires two spreadsheets, one of nodes, and another of edges to generate visual representations of social networks. Nodes, which in this instance are people (either publishers, printers, authors, booksellers, or preachers), are required to have a Label and a unique ID. The label is the full name of the person in question, and the ID I wanted to make for each person is meant to include the first three letters of their first name (if they were known), a period, and then the first four letters of their last name. Nodes in Gephi can also be given various characteristics, such as Type. I wanted to label
each node accordingly with a type that indicates whether the person in question was a publisher, a printer, an author, a bookseller, or a preacher.
Edges can be thought of as links between two people, and their strength in this representation was based on the frequency of which two people collaborated. In Gephi, edges must have a Source, a Target, and a Weight. The source is the first person (in the form of ID corresponding to their node), and the target is the second person they are being linked to (in the form of ID corresponding to their node). Weight is a measure of the strength of their relationship, which was based on frequency in this model. The more two people collaborated, the greater the weight of the edge between them.
Since it is rather tedious to track down how many times two people worked with each other through a slew of spreadsheets by hand (which Ava and Mia graciously did), I wrote two modules in Java that could efficiently clean data and get it ready for Gephi to make networks with, calculating both IDs for nodes and correctly creating edges with calculations of the number of times two people collaborated with each other. My code also kept track of what persons were publishers, authors, or printers etc. so that my nodes for Gephi could be correctly labeled with their respective Types.
I: DATA FORMATTING FOR THE CODE TO PROCESS
While the spreadsheets I discussed in the previous section were helpful for tracking down preliminary information, they were still not quite ready for my code to process. I went through each individual spreadsheet that was already created by hand and created a new spreadsheet that reformatted the information into something new that my code could process.
My new spreadsheet for code processing had two columns. One for the first node of the edge, and a second for the second node of the edge. Each entry linked two people, and for a single work on EEBO, every single relationship that could have existed between the persons listed on the work was given an entry. The names used for each person came from the standardized list of names that Amy Weng created.
Here is a screenshot of a section of the spreadsheet.
For the Euthymiae Raptus example, the spreadsheet entries would have been written as follows:
George Chapman:Author, Richard Bonian:Publisher George Chapman:Author, H Walley:Publisher George Chapman:Author, Humphrey Lownes:Printer Richard Bonian:Publisher, H Walley:Publisher
H Walley:Publisher, Humphrey Lownes:Printer Richard Bonian:Publisher, Humphrey Lownes:Printer
This way, authors were connected to the publishers they published with, publishers were connected to the printers they used, and printers were connected to the authors they printed. While it is possible that printers did not know authors and worked more closely with publishers in many instances, I thought it would be more meaningful to tease out connections by listing every single relationship that was possible given the names listed in an EEBO entry.
II: NodesandEdges
*For a more in-depth explanation of my code in a line by line manner, see the Full Code Write Up for Grad Students inside of the Git repository.
NodesandEdges is the first of the Java modules I wrote to process this new spreadsheet I had created. It contains 5 methods that create the nodes and edges necessary for a Gephi network.
The first method, buildIDs processes the spreadsheet and returns a dictionary/map where the keys are the names of people (labels for Gephi) and their corresponding values are the unique IDs needed for Gephi nodes. This is vital for getting the labels and IDs needed for the node spreadsheet Gephi requires.
The second method statusDictBuilder processes the spreadsheet and returns a dictionary/map where the keys are the names of people (labels for Gephi) and their corresponding values are the status of the person as either a publisher, printer, author, preacher, or bookseller. This method is helpful for keeping track of the different Types of nodes present so that Gephi can use this information to color nodes according to their status.
The third method printIDs generates the output of a node spreadsheet needed for Gephi with the data it prints organized with each line as the Label, ID, Type of an individual. The Type category corresponds to the status of someone as a publisher, author, printer, preacher, or bookseller. printIDs does this by using the existing dictionaries that were created by buildIDs and statusDictBuilder.
The fourth method buildRelationships processes the spreadsheet and returns a dictionary/map where the keys are the names of people and the corresponding value to each key is a list of the people they collaborated with. This is necessary in order to create the edges that Gephi will want in a separate spreadsheet.
The fifth method printSourceTargetWeight uses the prior dictionary built by buildRelationships to print the output of a Gephi edge spreadsheet. It prints line by line
as the ID of one person, the ID of their collaborator, and the number of times they collaborated.
III: DataCleaner
DataCleaner is the second module I wrote in Java to process the spreadsheet. It has 3 methods.
The first method readtoList acts as a file reader/scanner of the CSV version of the raw spreadsheet and converts it into an ArrayList of every name listed that is readable to the methods of NodesandEdges.
The second method getNamePairs acts as a file reader/scanner of the CSV version of the raw spreadsheet and converts it into an ArrayList of every single collaboration between people with each String entry being formatted as Name1&Name2. This is necessary for the way buildRelationships runs in NodesandEdges.
The third method is the main method. It calls all the functions from NodesandEdges to print the output of the Node spreadsheet for Gephi and the output for the Edge spreadsheet for Gephi with correct IDs and relationship strengths.
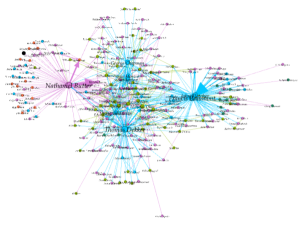
GEPHI NETWORKS AND FINDINGS
The above image is that of the network generated by Gephi using the spreadsheets created by NodesandEdges and DataCleaner. The different colors signify the status of individual people. Light blue means author, purple means publisher, orange means preacher, light green means printer, and dark green means bookseller.
There is a lot more “mess in the middle” of this network compared to the one generated by hand since this network links publishers to printers and printers to authors. However, the mass of overlap in the middle signifies that the varying social networks of the printing world frequently shared key participants in 17th century London. Further analysis of this “mess in the middle” is needed to understand what kinds of characteristics bound individuals together or made it likely for them to have collaborations in the first place.
NEXT STEPS AND FURTHER RECOMMENDATIONS
- Cross-reference entries with the Stationer’s Register to understand more about the relationships between key publishers, authors, and printers, as well as understand which stationers collaborated with what other stationers that would be missing from EEBO
- Analyze geographic location inside of Gephi and attempt to identify geographic clusters around certain locations of different publishers and printers, when the information is known
- Work to incorporate William Shakespeare into future Gephi network analysis, since he is a key figure missing and the collaborations he had and the publishers and printers he worked with will likely further elucidate relationships we want to know more about
- Reference the diary of Samuel Pepy’s when locations are inconsistent or share the same name but are in different places (such as St. Dunstan’s East and West and a potential third site) to further narrow down where publishers were located
- Research publishing families such as the Moseleys, the Okes, and the Alldes, as their connections are more difficult to pinpoint since individual members of each family are often not listed on the same work, but common trends in last names appear over thousands of EEBO entries
- Analyze the Gephi network through a temporal lens and pay attention to when certain authors, publishers, and printers exit and enter the timeline
https://github.com/sarahkonrad/Sarah-Konrad-Early-Modern-London-Fall-2022-
Contributors: Sarah Konrad, Mia Malden, Ava Raffel
Written by: Sarah Konrad