In an earlier post I described the setup of the new v3.4 perfSONAR node used to test the AL2S network. In this post I will summarize the results of the 1 week test done on the AL2S link to UChicago along with a description of the work that Victor did to setup the link.
Setup
The TelCom Arista has a PerfSonar box connected to it, on port 17.
The TelCom Arista *also* has a connection to AL2S, via MCNC, that arrives via port 1.
We share the connection through AL2S with RENCI, and RENCI has allocated us 100 VLAN tags to use (1000-1099, inclusive).
Last week, Victor allocated a 5 Gbps circuit for testing between Duke and Chicago.
It is using VLAN tag 1000 (on our end), and expired at 4 PM on Monday (10/20/14).
AL2S performs a tag flip somewhere in the link, so that our VLAN tag 1000 becomes VLAN tag 3000 at Chicago’s end.
The first thing we did was to test in traditional switch mode.
This meant:
1) Allocating VLAN 1000 on the TelCom Arista
2) Ensuring that port 1 was in trunk mode, and that tags 1000-1099 were allowed
3) Ensuring that port 17 was in access mode for tag 1000
4) Setting up a VLAN interface for tag 1000
We agreed with Chicago to use the private subnet 192.168.10.0/24 for testing.
The VLAN interface on the TelCom Arista was configured to use address 192.168.10.2; the Chicago switch was configured to use 192.168.10.1.
After confirming connectivity between the switches, the PerfSonar boxes at each end were configured with addresses 192.168.10.3 (Duke) and 192.168.10.4 (Chicago).
Once we had done a bit of testing in traditional switch mode, we chose to test the OpenFlow capability, using rest_router.
To set this up, Victor did the following:
1) Add port 1 to the OpenFlow instance on the TelCom Arista
2) Add port 17 to the OpenFlow instance on the TelCom Arista
3) Configure port 17 into trunk mode on the TelCom Arista; ports in access mode do not function in OpenFlow mode
4) Add a vlan tagged interface to the PerfSonar box hanging off port 17; this was accomplished thus:
a) ifconfig p2p1 0.0.0.0
b) modprobe 8021q
c) vconfig add p2p1 1000
d) ifconfig p2p1.1000 192.168.10.3 netmask 255.255.255.0 up mtu 9000
5) Add the private address range to rest_router’s management using curl, thus:
curl -X POST -d ‘{“address”:”192.168.10.254/24″}’ http://sdn-prod-01.oit.duke.edu:8080/router/0000001c7365b107/1000
At this point, packets were being switched onto the AL2S link, within the TelCom Arista, using OpenFlow rules.
Since roughly Tuesday afternoon, perfSonar running measurements against the peer perfSonar box at Chicago.
The bandwidth data has been pretty noisy, both with traditional switching and with OpenFlow.
We expect that there’s some bandwidth contention; and would be curious to see how the results look with bwctl being run in parallel mode within the web interface.
When bwctl is run manually (and explicitly specify the degree of parallelism), we get fairly consistent (and high) results that exceed the requested bandwidth of the link (typically very close to 10 Gbps –
Command Line BWCTL Results:
[root@tel-perfsonar-01 ~]# bwctl -c 192.168.10.4 -P8 bwctl: Using tool: iperf bwctl: 36 seconds until test results available RECEIVER START ------------------------------------------------------------ Server listening on TCP port 5239 Binding to local address 192.168.10.4 TCP window size: 87380 Byte (default) ------------------------------------------------------------ [ 15] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 57265 [ 17] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 49730 [ 16] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 58667 [ 18] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 53343 [ 19] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 41485 [ 20] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 55678 [ 21] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 39032 [ 22] local 192.168.10.4 port 5239 connected with 192.168.10.3 port 39575 [ ID] Interval Transfer Bandwidth [ 22] 0.0-10.0 sec 3123445760 Bytes 2488803881 bits/sec [ 22] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 17] 0.0-10.1 sec 1780350976 Bytes 1413963232 bits/sec [ 17] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 15] 0.0-10.1 sec 1054474240 Bytes 832376766 bits/sec [ 15] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 21] 0.0-10.1 sec 1462370304 Bytes 1154438086 bits/sec [ 21] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 18] 0.0-10.2 sec 1421213696 Bytes 1117543689 bits/sec [ 18] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 20] 0.0-10.2 sec 1135476736 Bytes 890163568 bits/sec [ 20] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 16] 0.0-10.2 sec 858259456 Bytes 672128900 bits/sec [ 16] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [ 19] 0.0-10.2 sec 930742272 Bytes 727474666 bits/sec [ 19] MSS size 8948 bytes (MTU 8988 bytes, unknown interface) [SUM] 0.0-10.2 sec 11766333440 Bytes 9196648461 bits/sec Wed Oct 15 14:06:26 EDT 2014
Which shows about 9.2 Gbps which is great.
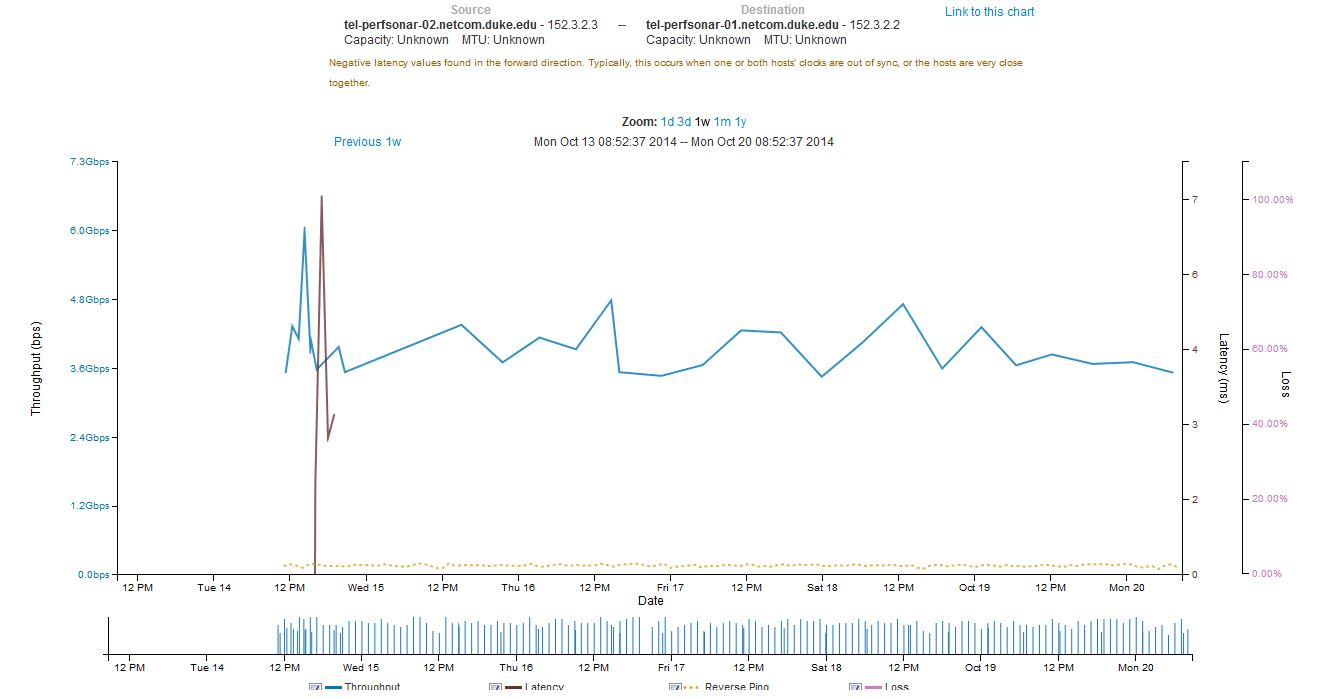
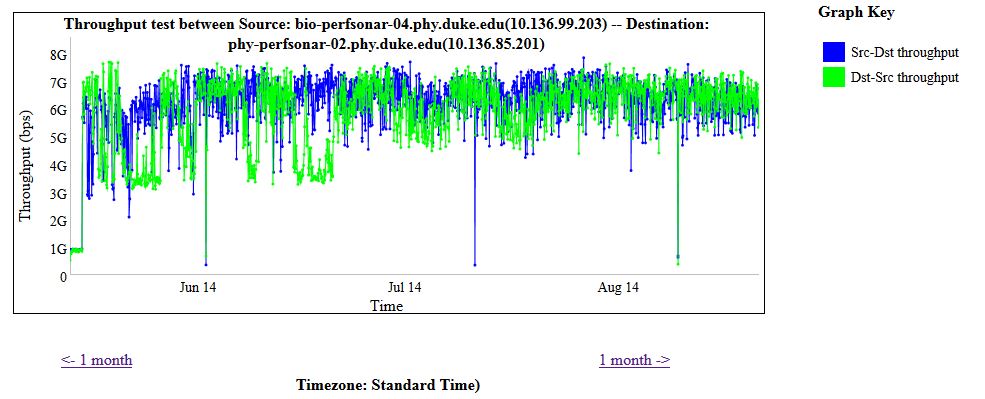
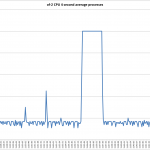
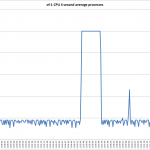
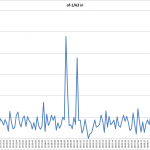
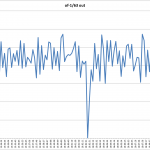
The full results for the bandwidth testing using the perfSONAR GUI is shown below:
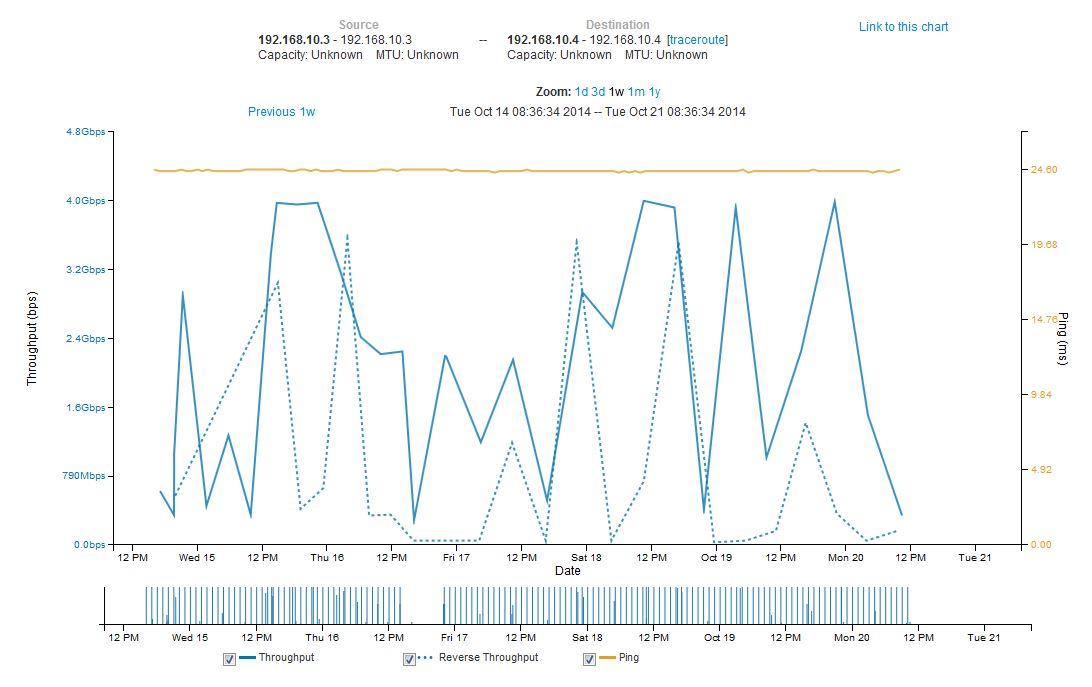
A couple of items to note –
- General variation of the bandwidth – inbound and outbound bandwidth over the link to the UChicago perfSONAR node varied broadly.
- Consistency of ping times – the ping times from tel-perfsonar-01 (192.168.10.3) to the UChicago node (192.168.10.4) where rock solid at 24.6 msec and did not vary when the Arista switch was in normal mode vs. OpenFlow mode.
- The lack of data between 4PM and 10 PM on Thursday 10/16/14 was due to Charley incorrectly setting the IP address on the primary network interface (p2p2) which Victor fixed late Thursday evening.