


“It was the ‘Wizard of Oz’ in digital format as the four titans of Big Tech testified via video before the House Antitrust Subcommittee. Just like in the movie, what the subcommittee saw was controlled by a force hidden from view. The wizard in this case – the reason these four companies are so powerful – is the math that takes our private information and turns it into their corporate asset.”
—Tom Wheeler, ex-Chairman of US Federal Communications Commission (2013–2017)
Digital personal data is often described as the resource of the future. In 2011, the World Economic Forum defined it as a “new asset class” that “is generating a new wave of opportunity for economic and societal value creation.” The importance of personal data is evident in the rise of so-called “Big Tech”—consisting of Apple, Amazon, Microsoft, Alphabet/Google, and Facebook—as the dominant firms in our society today (see the graph below). Big Tech firms have inserted themselves into our lives as key social and economic intermediaries, providing often essential services, products, and infrastructures, all of which we use in exchange for handing over our personal data. Our personal data seem to be the key asset for these Big Tech firms—and other digital technology firms like them—providing an important new means for investors to evaluate future growth and success. Consequently, data governance, or how we measure and value personal data, has become a major issue in policy and business circles.
Big Tech’s share of S&P500 total capitalization, 2013–2020
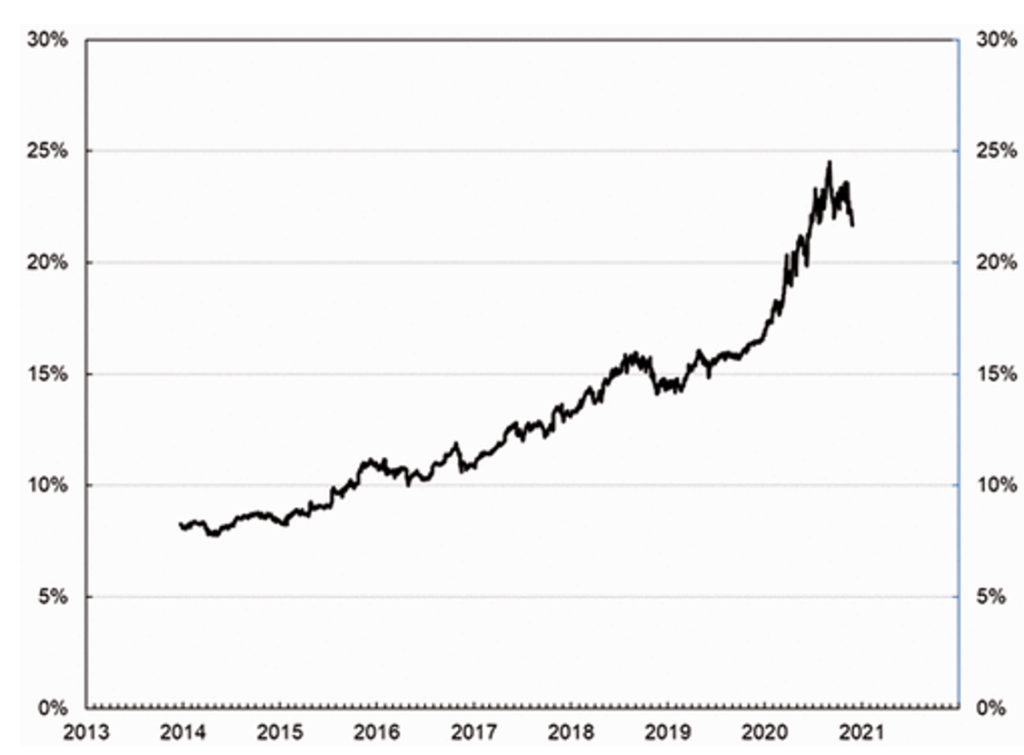
Note: Series calculated by authors with data from Barchart, Global Financial Data, and Yahoo Finance. Series begins December 23, 2013, the day of Facebook’s inclusion in the index.
In a recent article, we explored how Big Tech measures and values our personal data in order to unpack these data governance issues.
We started by trying to measure the personal data held by Big Tech firms and how this contrasts with other US firms. We looked at the asset base of the Top 200 US corporations, which showed a significant decline in tangible assets and a rise in intangibles between 1950 and 2020. Between the early 1980s, tangibles shrank from nearly 60% of total corporate assets to less than 30% today. In turn, the intangibles share rose from less than 1% to more than 30% in 2016, when they surpassed tangibles. We can explain part of this trend by pointing to changes in accounting practices, as well as increase in mergers and acquisitions (M&A), and industrial transformation. But it is reasonable to assume that a growing portion of the intangible asset base can be attributed to personal data. However, that does not seem to be the case after we examined the Big Tech firms.
For example, Amazon, Google, and Facebook are moving against the Top 200’s trend of a declining share of tangibles and a growing share of intangibles. Since their IPOs, all three have more than doubled the share of tangible assets in their asset base. As of 2019, Google and Facebook both had a slightly higher proportion of tangible assets than the average Top 200 firm. Intangibles provide an even starker contrast: while the Top 200 have about 30% of their assets in intangibles, Amazon and Google’s intangibles comprise less than 10% of their assets, with Facebook’s intangibles at 15%. Apple even stopped reporting on their intangible assets in 2018. These findings contrast with our assumption that Big Tech’s asset base would be defined by their collection of personal data, or that investment in intangibles is their main competitive strategy.
To understand our findings, we looked at the ambiguities in the financial valuation of Big Tech—why they have such high market capitalization—since their balance sheets don’t seem to reflect expectations about their key assets (i.e., personal data). Since we cannot identify where “data assets” sit in accounting terms, we approached the question by looking at how Big Tech firms and their investors frame personal data in their earnings calls and financial reports.
Typically, an earnings call consists of a presentation by a corporate executive (e.g., CEO, CFO) that is then followed by a question and answer (Q&A) session where analysts can ask questions about recent financial results and future plans. If Big Tech consider personal data to be an important although unaccounted asset, we expected analysts to ask for information about personal data so they could work out how it is being managed and valued by firms. Our analysis of 10 years’ worth of earnings calls of these Big Tech firms showed that there was almost no expressed interest in personal data per se. We carried out a quantitative textual analysis of these earnings calls, and it showed that “personal data” was not even mentioned a handful of times in nearly a decade. Rather than personal data, the immediate concern of the analysts was “monetization,” and the preferred techno-economic object of monetization was “users.” Here, users were framed as part of a broader techno-economic assemblage—identified as an “ecosystem”—capable of generating revenue if it was properly monetized.
Our findings showed that it is the users that are understood as assets. This conclusion entails a specific form of data governance predicated on the monetization of user data within digital “ecosystems.” This is because Big Tech cannot de jure own personal data as an asset, as illustrated by the near absence of references to personal data in earnings calls. Instead, users are assetized—turned into assets—through (1) the deployment of standards and digital architectures to measure and delineate users and usage; (2) the configuration of users within an ecosystem; (3) the contractual (i.e., terms of service) and technical (i.e., interoperability restrictions) enclosure of user and usage metrics for different purposes (e.g., training algorithms, data analytics); and (4) the capitalization of future revenues derived from different monetization mechanisms, including locking-in users to digital ecosystems (e.g., Apple), offering subscription services (e.g., Microsoft), selling access to users and user data (e.g., Facebook, Google), or collecting a range of fees for use of a platform (e.g., Amazon).
We concluded that Big Tech are measuring and valuing users and user metrics collected within and through their ecosystems. We called this “techcraft”—echoing the arguments of James C. Scott on “statecraft”—since it involves making a particular kind of data (i.e., user metrics) measurable and legible as an asset to Big Tech and their investors. Acquisitions provide a snapshot of this assetization process, where innovation and business strategies are specifically valued on the back of the generation of user numbers, user engagement, user clicks, click-through rates, and so on. Users and user engagement are the thing being valued as assets by Big Tech firms and market actors, even if it does not show up on balance sheets. Monetization of users and user engagement is based on selling access to users and access to users is controlled via (1) the legal rights that users sign over to firms and (2) the techno-economic configuration of user engagement through technological capture (e.g., Like buttons, cookies, etc.). User engagement is measurable, legible, and valuable because it drives an extraction-as-service or subscription-based business model, entailing repeat revenue streams rather than one-off earnings. Of particular importance is the fact that users indefinitely sign away their legal rights in ubiquitous terms and conditions contracts that can be amended at will by Big Tech. Furthermore, users indirectly sign away their friends and families’ rights through third-party permissions embedded in numerous apps.
In conclusion, it is important to note that despite the power of Big Tech, there is a real threat to their dominance arising from their data governance practices. People are not “users,” yet they are reconfigured as these techno-economic objects. Personal data is not “user engagement,” yet it is frequently understood, measured, and made legible as such. Building on claims made by Shoshana Zuboff and others about surveillance capitalism, especially her notion of “prediction products,” we argued that the reconfiguring of people (and personal data) as users and user engagement through techcraft makes these entities measurable and legible only in these terms, without a requirement that they translate into actual changed behavior (e.g., changing spending behavior). Consequently, the simulation of “users” and “user engagement” can very easily disrupt and distort the measurement, governance, and valuation of user data on which Big Tech relies. For example, bots, click farms, and other automated processes simulating user activity can and will significantly undermine trust in Big Tech’s supposedly key assets over time. This is outlined in Tim Hwang’s new book on the Subprime Attention Crisis, which offers a contrasting take—from Zuboff’s—on how personal data is governed in contemporary capitalism.
Kean Birch is an Associate Professor at York University, Canada
D.T. Cochrane is a Postdoctoral Fellow at York University, Canada
Callum Ward is a Research Fellow at UCL, UK
This post is adapted from their paper, “Data as asset? The Measurement, governance, and valuation of digital personal data by BigTech”, published in the journal Big Data & Society.